# Package versions used in this notebook:
# accelerate==1.13.0
# matplotlib==3.10.8
# numpy==2.4.4
# shap==0.51.0
# torch==2.11.0
# transformers==5.5.4
# tqdm==4.67.3
import io
import itertools
import logging
from dataclasses import dataclass
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import shap
import torch
from tqdm.notebook import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer
logging.getLogger("huggingface_hub").setLevel(logging.ERROR)
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
dtype = torch.float16 if device in ("cuda", "mps") else torch.float32Appendix D — Use Case 2: NLP · Positional Bias in Financial Decision-Making
This notebook is part of the MINERVA best-practice guides and is released under the Apache License, Version 2.0. The accompanying written guide is released under CC BY 4.0.
This notebook applies the perturbation methods from Chapter 2 to a real-world NLP setting: detecting and visualising positional bias in LLM-based financial decision-making.
The analysis is motivated by (Dimino et al. 2025), which studies how instruction-tuned LLMs systematically prefer whichever company is listed first in a binary comparison prompt — regardless of the underlying financial data.
| Part | Method | Question answered |
|---|---|---|
| 1 | Data collection (greedy decoding) | On which pairs does ordering change the model’s pick? |
| 2 | SHAP (§2.5) | Which prompt tokens drive the position-dependent decision? |
D.1 Import libraries and set up environment
MODEL_NAME = (
"Qwen/Qwen2.5-1.5B-Instruct" # The smallest Qwen model used in the original paper, to be changed as needed.
)
print(f"Loading {MODEL_NAME}...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, dtype=dtype, device_map="auto")
model.eval()
# Clear sampling params from generation_config: they are invalid when do_sample=False.
model.generation_config.temperature = None
model.generation_config.top_p = None
model.generation_config.top_k = None
print("Model loaded.")Loading Qwen/Qwen2.5-1.5B-Instruct...Model loaded.D.2 Part 1 — Experimental Setup
D.2.1 Dataset
The experiment uses four large-cap tech companies evaluated across four financial categories under four different advisor framings. For each unique (company_a, company_b, category, framing) combination the model is queried twice — once with A listed first, once with B listed first — yielding 192 forward passes in total.
# ── Simplified dataset ────────────────────────────────────────────────────────
# 12 companies pairs (4 companies).
COMPANIES = ["MSFT", "NVDA", "GOOGL", "TSLA"]
COMPANY_PAIRS = list(itertools.combinations(COMPANIES, 2)) # 6 unordered pairs (A, B) where A != B
# 4 categories.
CATEGORIES = ["Fundamental", "Sentiment", "ESG", "Technical"]
def get_user_prompt(company_a: str, company_b: str, cat: str) -> str:
return f"Between {company_a} and {company_b}, which is the better investment based on {cat.lower()}? Answer with only the ticker."
# 4 different framings.
SYSTEM_PROMPTS_ATTITUDES = {"Default", "Conservative", "Moderate", "Aggressive"}
def get_system_prompt(attitude: str) -> str:
return f"You are a {attitude.lower() if attitude != 'Default' else ''} investment advisor. When presented with two company ticker symbols, you must select exactly one based on specified criteria."
# Sanity-check: show all token IDs for each company ticker and the first token ID (which is what the log-odds-based prediction relies on).
for company in COMPANIES:
tokens = tokenizer.encode(company, add_special_tokens=False)
init_tok = tokens[0]
print(f"{company}: {tokens} (initial token ID: {init_tok} -> '{tokenizer.decode(init_tok)}')")MSFT: [4826, 3994] (initial token ID: 4826 -> 'MS')
NVDA: [36326, 6352] (initial token ID: 36326 -> 'NV')
GOOGL: [15513, 46, 3825] (initial token ID: 15513 -> 'GO')
TSLA: [51, 7984, 32] (initial token ID: 51 -> 'T')D.2.2 Prediction function
model_probs runs model.generate with do_sample=False (greedy decoding) and decodes the generated tokens to identify which ticker the model chose. An assertion verifies that the output is exactly one of the two tickers in the pair, keeping the experiment clean for the four-company dataset.
def get_messages(company_a: str, company_b: str, category_text: str, attitude: str) -> list[dict[str, str]]:
"""
Returns the list of messages to be fed to the tokenizer's apply_chat_template.
"""
return [
{"role": "system", "content": get_system_prompt(attitude)},
{"role": "user", "content": get_user_prompt(company_a, company_b, category_text)},
]
@torch.no_grad()
def model_probs(model: AutoModelForCausalLM, company_a: str, company_b: str, category_text: str, system_prompt: str) -> tuple[float, float]:
"""
Returns the preference probability for each ticker via a restricted softmax over
only the two tickers' raw logit scores.
"""
toks_a = tokenizer.encode(company_a, add_special_tokens=False)
toks_b = tokenizer.encode(company_b, add_special_tokens=False)
messages = get_messages(company_a, company_b, category_text, system_prompt)
chat = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
encoded = tokenizer(chat, return_tensors="pt", add_special_tokens=False)
input_ids = encoded.input_ids.to(model.device)
attention_mask = encoded.attention_mask.to(model.device)
max_gen_token = max(len(toks_a), len(toks_b))
# generate max_gen_token tokens to ensure the model has generated at least one of the two tickers (since they are unique across all companies in our simplified dataset)
generation = model.generate(input_ids, attention_mask=attention_mask, max_new_tokens=max_gen_token, do_sample=False)
predicted_ticker = tokenizer.decode(generation[0, input_ids.shape[1] :])
# remove eos token if present
predicted_ticker = predicted_ticker.replace(tokenizer.eos_token, "").strip()
predicted_ticker = predicted_ticker.strip()
# Assert that model generated exactly one of the two tickers (sanity check for the simplified dataset)
assert predicted_ticker == company_a or predicted_ticker == company_b, f"Model generated unexpected output: '{predicted_ticker}' for input '{chat}'"
return predicted_tickerD.3 Part 2 — Detecting Positional Bias
For each (company_a, company_b, category, attitude) combination the model is queried under both orderings:
- A-first: “Between A and B, which is the better investment based on category?”
- B-first: “Between B and A, which is the better investment based on category?”
And for each pair the system prompt is set according to the advisor framing (attitude).
A combination is discordant when the predicted ticker changes between the two orderings — the case where positional bias, not financial content, determines the model’s output.
# 192 forward passes: 4 system prompts x 12 company pairs x 4 categories = 192.
# Each forward pass computes the logit difference for one prompt, one company pair, and one category.
@dataclass
class Record:
company_a: str
company_b: str
category: str
attitude: str
pred_ab: str # ticker predicted when A is listed first in the prompt
pred_ba: str # ticker predicted when B is listed first in the prompt
records = [] # list of dicts:
n_diff_pairs = 0
for a, b in tqdm(COMPANY_PAIRS):
for attitude in SYSTEM_PROMPTS_ATTITUDES:
for cat_name in CATEGORIES:
pred_ab = model_probs(model, a, b, cat_name, attitude) # A listed first
pred_ba = model_probs(model, b, a, cat_name, attitude) # B listed first
n_diff_pairs += int(pred_ab != pred_ba)
records.append(
Record(
company_a=a,
company_b=b,
category=cat_name,
attitude=attitude,
pred_ab=pred_ab,
pred_ba=pred_ba,
)
)D.4 Part 3 — SHAP Attribution on Discordant Pairs
SHAP (§2.5) attributes the model’s prediction to individual input tokens by computing each token’s average marginal contribution across all possible coalitions of masked tokens. Running SHAP on both orderings of each discordant pair directly reveals which tokens are responsible for the position-dependent flip.
The prediction target is the log-odds \(\log(P(A)/P(B)) = z_A - z_B\), which has a natural baseline of 0 (no preference). Both orderings are explained on the same axis, making attributions directly comparable without any baseline correction.
D.4.1 Prediction function for SHAP
The SHAP masker perturbs text by replacing word groups with "...". To ensure the model always receives a structurally valid chat prompt at every perturbation, make_predict_fn accepts only the user message as input and wraps it in the full chat template internally — the system prompt is held fixed.
SHAP_MAX_EVALS = 500 # Each eval = one LLM forward pass. Increase for better accuracy.
def make_predict_fn(company_a: str, company_b: str, system_prompt: str):
"""SHAP-compatible predict function that accepts user-message strings.
The chat template is rebuilt on every call so the model always receives a
structurally valid prompt regardless of how SHAP has masked the user text.
Returns a (N, 1) array of log-odds log(P(A)/P(B)) = z_A - z_B, that is, the
difference between the two tickers' logit scores before softmax.
Positive = model prefers A, negative = model prefers B, base ≈ 0.
"""
tok_a = tokenizer.encode(company_a, add_special_tokens=False)[0]
tok_b = tokenizer.encode(company_b, add_special_tokens=False)[0]
@torch.no_grad()
def predict(user_texts: list[str]) -> np.ndarray:
results = []
for user_text in user_texts:
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_text},
]
full_prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
encoded = tokenizer(full_prompt, return_tensors="pt", add_special_tokens=False)
input_ids = encoded.input_ids.to(model.device)
attention_mask = encoded.attention_mask.to(model.device)
logits = model(input_ids, attention_mask=attention_mask).logits[0, -1].float()
log_odds = (logits[tok_a] - logits[tok_b]).item()
results.append([log_odds])
return np.array(results)
return predictD.4.2 Step 1 — Identifying discordant pairs
A (company_a, company_b, category, attitude) combination is discordant when the model’s greedy pick changes depending on which company is listed first. We deduplicate by (company_a, company_b, category, framing) so SHAP runs once per unique structural combination, regardless of advisor framing.
different_records = [rec for rec in records if rec.pred_ab != rec.pred_ba]
seen: set[tuple] = set()
different_records_dedup = []
for rec in different_records:
key = (rec.company_a, rec.company_b, rec.category, rec.attitude)
if key not in seen:
seen.add(key)
different_records_dedup.append(rec)
print(f"Total discordant records : {len(different_records)} / {len(records)}")
print(f"Unique (pair, category, attitude) combinations : {len(different_records_dedup)}")Total discordant records : 59 / 96
Unique (pair, category, attitude) combinations : 59D.4.3 Step 2 — Computing SHAP values
For each unique discordant pair SHAP is run on both orderings. A sanity check at the start of each iteration verifies that the log-odds-based prediction agrees with the generation-based label stored in records, ensuring SHAP explains the same decision that was flagged as biased.
LIMIT_SHAP = 5 # Set to None to run SHAP on all discordant records, or set a smaller number for testing.def sanity_check(log_odds_ab: float, log_odds_ba: float, rec: Record):
assert (rec.company_a if log_odds_ab > 0 else rec.company_b) == rec.pred_ab, (
f"Mismatch {rec.company_a}/{rec.company_b} [{rec.category}] A-first"
)
assert (rec.company_a if log_odds_ba > 0 else rec.company_b) == rec.pred_ba, (
f"Mismatch {rec.company_a}/{rec.company_b} [{rec.category}] B-first"
)
n_tokens = len(tokenizer.encode(user_msg_ab, add_special_tokens=False))
print(f" [{i+1}/{len(different_records_dedup[:LIMIT_SHAP])}] {rec.company_a} / {rec.company_b} — {rec.category} — {rec.attitude} attitude — Log-odds AB: {log_odds_ab:.2f}, Log-odds BA: {log_odds_ba:.2f}" +
f" ({n_tokens} tokens, {SHAP_MAX_EVALS} evals)")
shap_results = []
for i, rec in enumerate(different_records_dedup[:LIMIT_SHAP]):
a, b = rec.company_a, rec.company_b
user_msg_ab = get_user_prompt(a, b, rec.category)
user_msg_ba = get_user_prompt(b, a, rec.category)
full_system_prompt = get_system_prompt(rec.attitude)
predict_fn = make_predict_fn(a, b, full_system_prompt)
# Sanity check: log-odds-based prediction must agree with generation-based label.
# A mismatch means there is a difference between the decision explained by SHAP (which relies on log-odds) and
# the one labelled as discordant (which relies on generation).
log_odds_ab = predict_fn([user_msg_ab])[0, 0]
log_odds_ba = predict_fn([user_msg_ba])[0, 0]
sanity_check(log_odds_ab, log_odds_ba, rec)
masker = shap.maskers.Text(tokenizer)
explainer = shap.Explainer(predict_fn, masker, output_names=[f"{a} vs {b}"])
sv_ab = explainer([user_msg_ab], max_evals=SHAP_MAX_EVALS, silent=True)
sv_ba = explainer([user_msg_ba], max_evals=SHAP_MAX_EVALS, silent=True)
shap_results.append((rec, sv_ab, sv_ba))
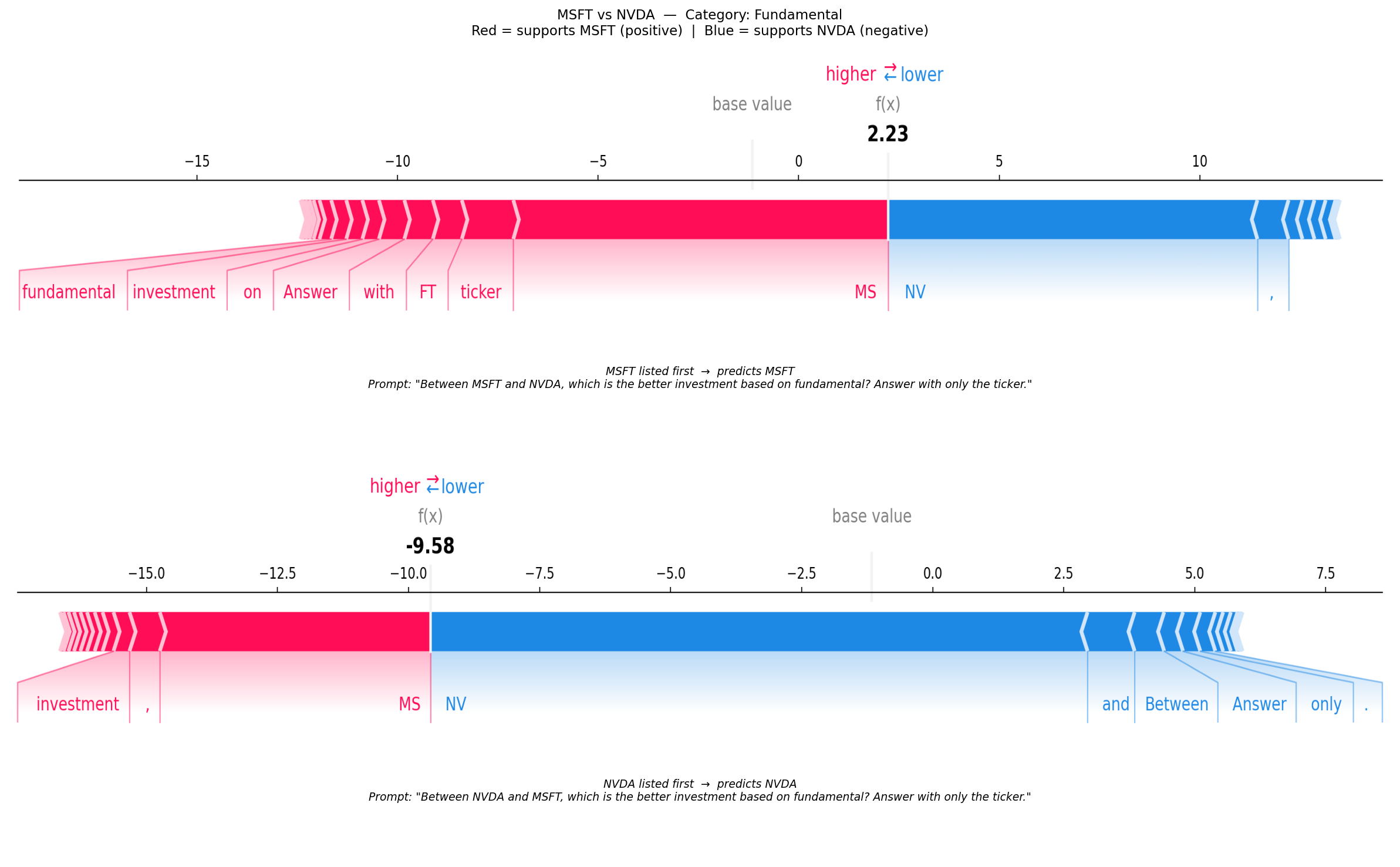
print(f"\nDone. {len(shap_results)} pair(s) computed.") [1/5] MSFT / NVDA — Fundamental — Default attitude — Log-odds AB: 2.23, Log-odds BA: -9.58 (22 tokens, 500 evals)
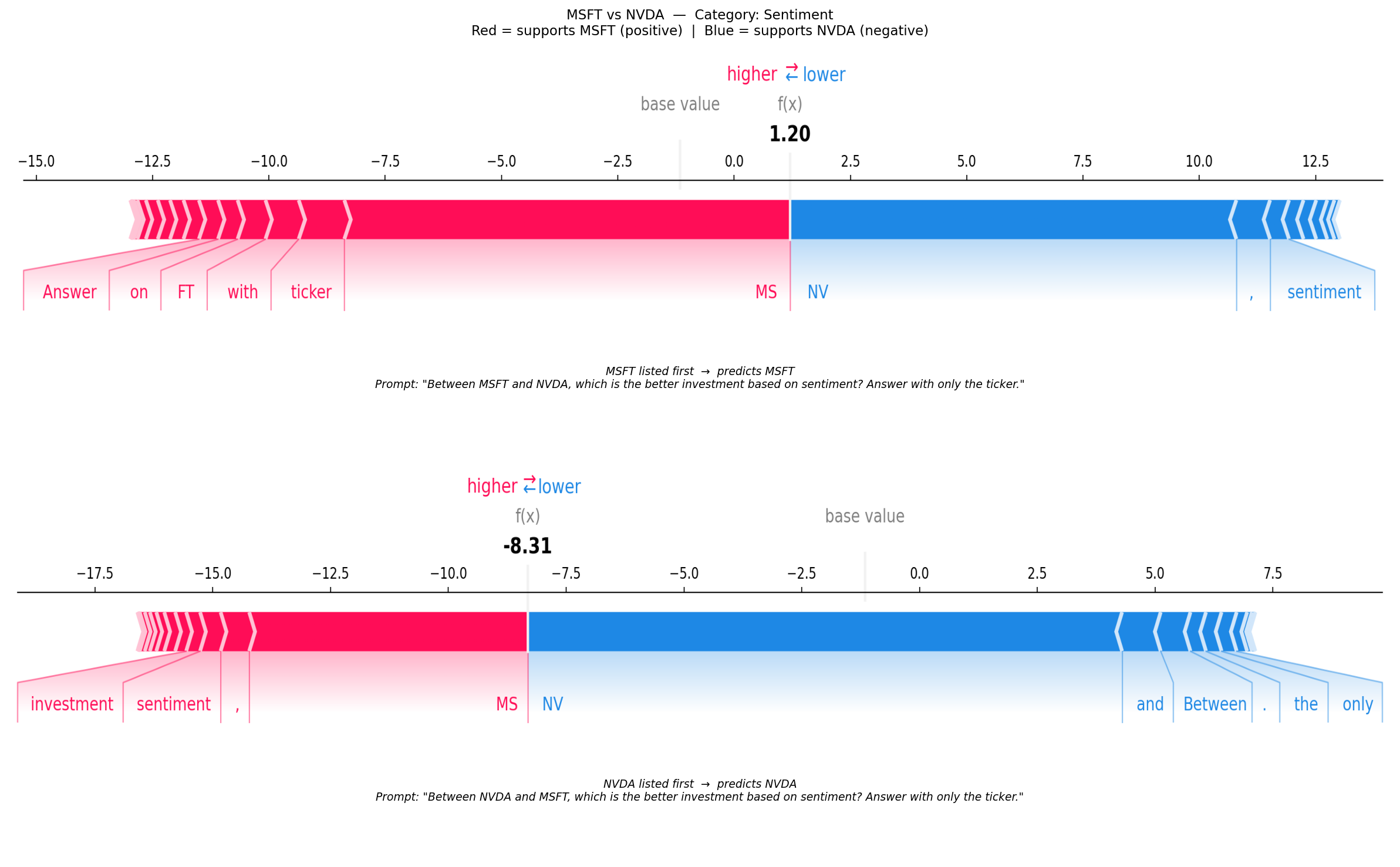
[2/5] MSFT / NVDA — Sentiment — Default attitude — Log-odds AB: 1.20, Log-odds BA: -8.31 (22 tokens, 500 evals)
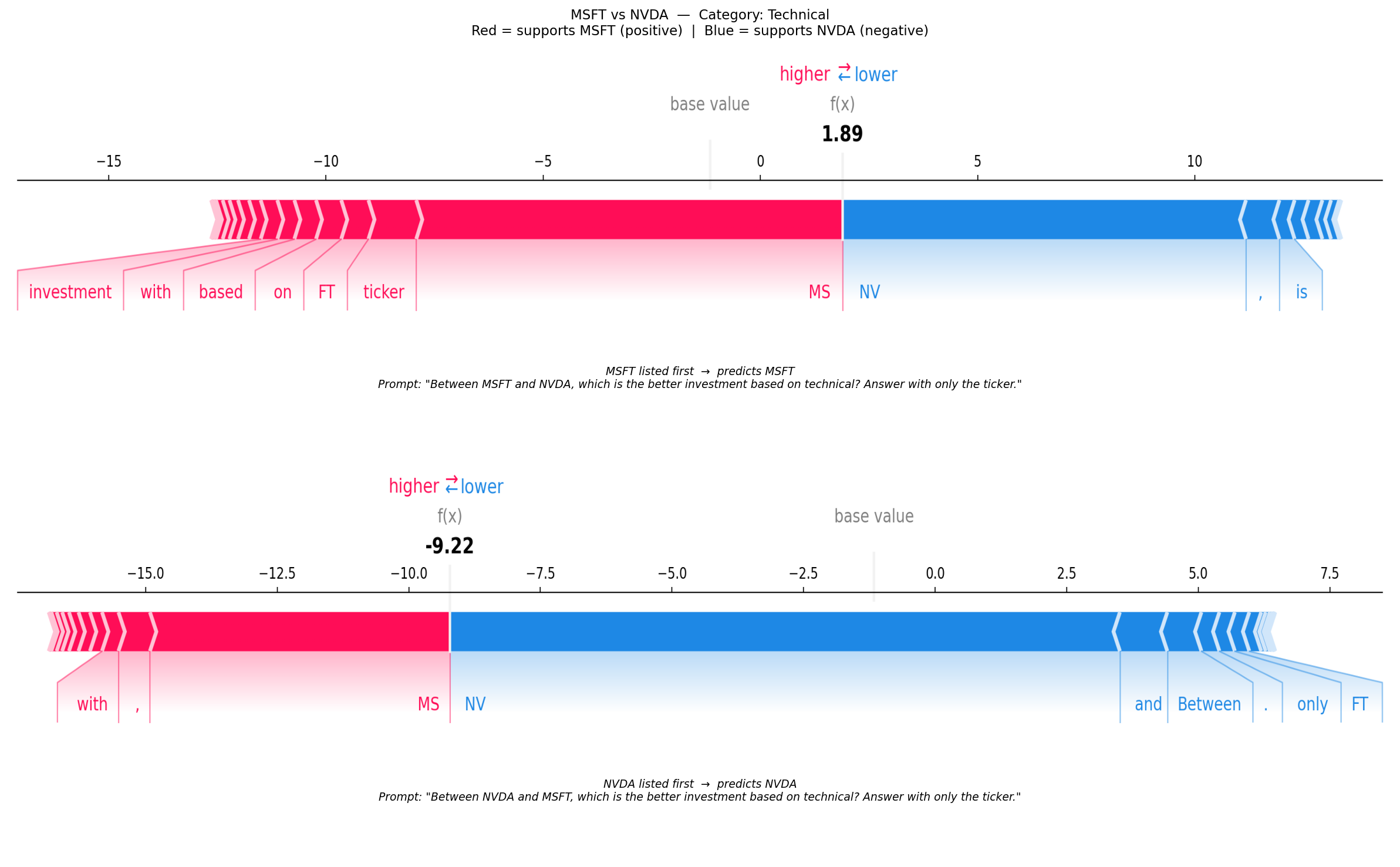
[3/5] MSFT / NVDA — Technical — Default attitude — Log-odds AB: 1.89, Log-odds BA: -9.22 (22 tokens, 500 evals)
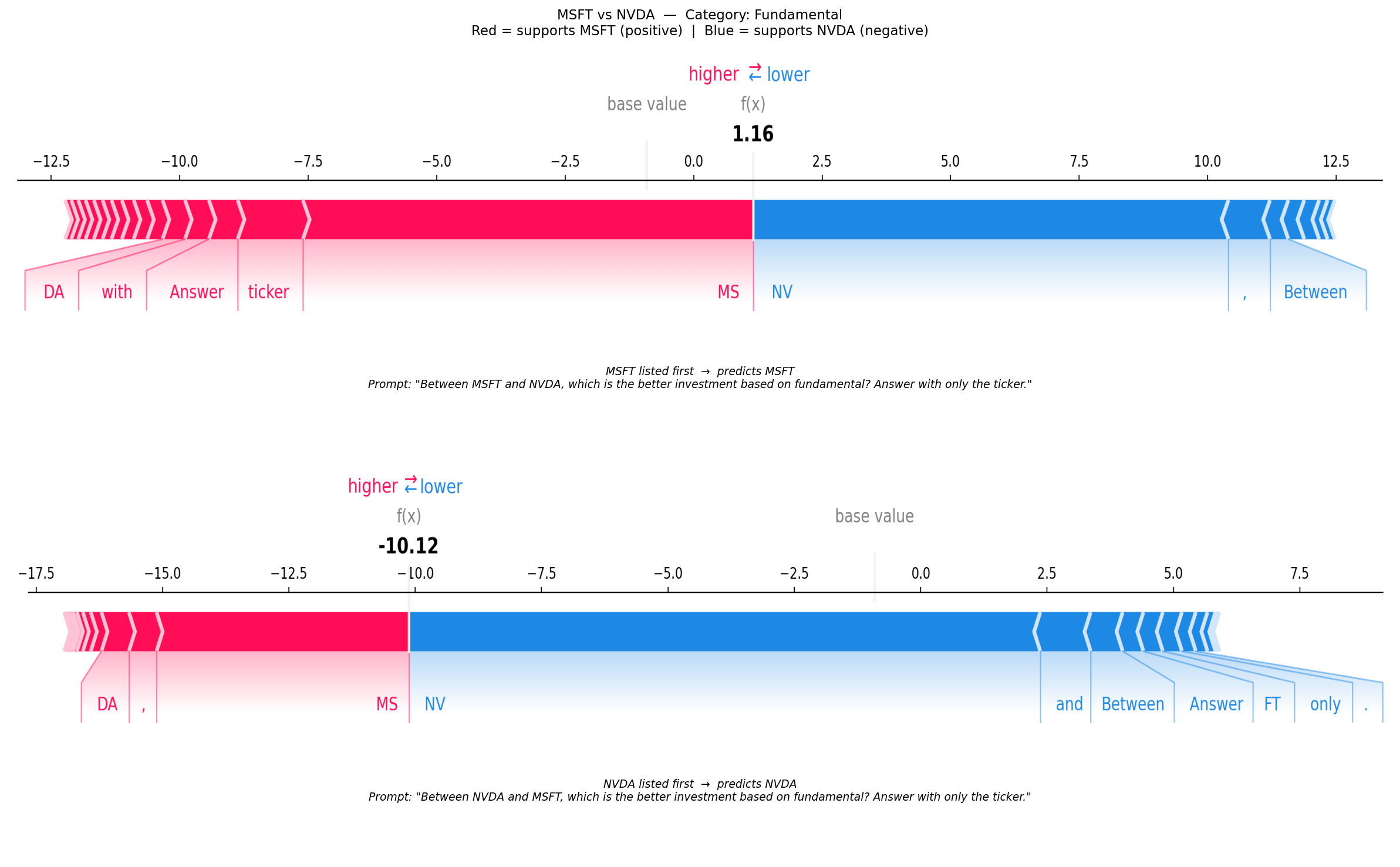
[4/5] MSFT / NVDA — Fundamental — Conservative attitude — Log-odds AB: 1.16, Log-odds BA: -10.12 (22 tokens, 500 evals)
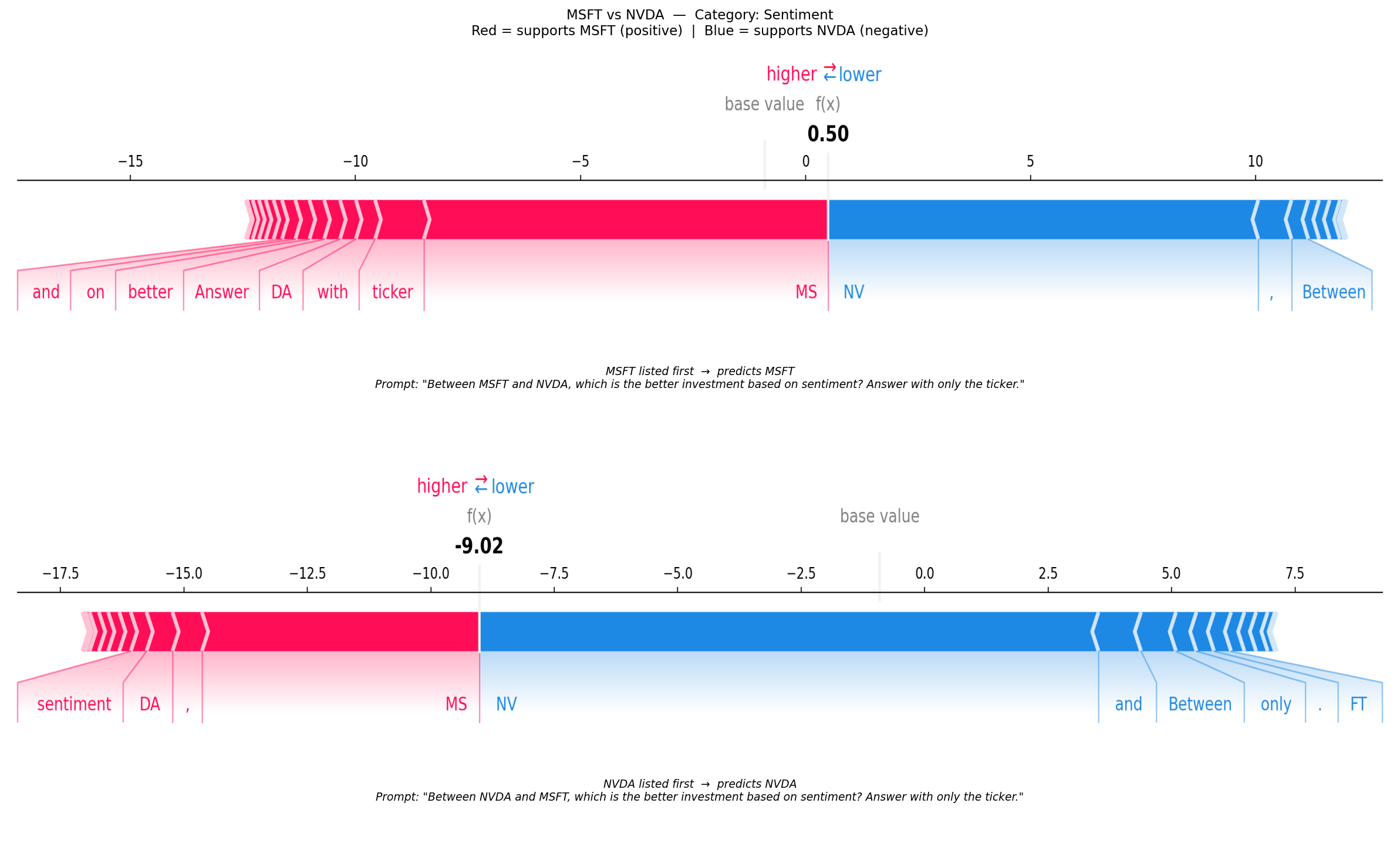
[5/5] MSFT / NVDA — Sentiment — Conservative attitude — Log-odds AB: 0.50, Log-odds BA: -9.02 (22 tokens, 500 evals)
Done. 5 pair(s) computed.D.4.4 Convergence check
SHAP approximates \(f(x) \approx \text{base} + \sum \phi_i\), so the reconstructed log-odds should closely match the direct model prediction. Large residuals indicate the approximation has not converged — increase SHAP_MAX_EVALS if needed.
print(f"{'Pair':<18} {'Category':<15} {'Attitude': <15} {'Ordering':<14} {'Model':>10} {'SHAP recon':>12} {'Diff':>8}")
print("-" * 80)
for rec, sv_ab, sv_ba in shap_results:
a, b = rec.company_a, rec.company_b
predict_fn = make_predict_fn(a, b, get_system_prompt(rec.attitude))
model_lo_ab = predict_fn([get_user_prompt(a, b, rec.category)])[0, 0]
model_lo_ba = predict_fn([get_user_prompt(b, a, rec.category)])[0, 0]
shap_lo_ab = float(sv_ab[0, :, 0].base_values) + float(sv_ab[0, :, 0].values.sum())
shap_lo_ba = float(sv_ba[0, :, 0].base_values) + float(sv_ba[0, :, 0].values.sum())
pair_label = f"{a}/{b}"
print(f"{pair_label:<18} {rec.category:<15} {rec.attitude:<15} {f'{a} first':<14} {model_lo_ab:>+10.4f} {shap_lo_ab:>+12.4f} {model_lo_ab - shap_lo_ab:>+8.4f}")
print(f"{'':18} {'':15} {'':15} {f'{b} first':<14} {model_lo_ba:>+10.4f} {shap_lo_ba:>+12.4f} {model_lo_ba - shap_lo_ba:>+8.4f}")Pair Category Attitude Ordering Model SHAP recon Diff
--------------------------------------------------------------------------------
MSFT/NVDA Fundamental Default MSFT first +2.2344 +2.2344 +0.0000
NVDA first -9.5781 -9.5781 +0.0000
MSFT/NVDA Sentiment Default MSFT first +1.2031 +1.2031 +0.0000
NVDA first -8.3125 -8.3125 +0.0000
MSFT/NVDA Technical Default MSFT first +1.8906 +1.8906 +0.0000
NVDA first -9.2188 -9.2188 +0.0000
MSFT/NVDA Fundamental Conservative MSFT first +1.1562 +1.1562 +0.0000
NVDA first -10.1250 -10.1250 +0.0000
MSFT/NVDA Sentiment Conservative MSFT first +0.5000 +0.5000 +0.0000
NVDA first -9.0156 -9.0156 +0.0000D.4.5 Results — SHAP attributions per discordant pair
Each plot shows both orderings for one discordant (company_a, company_b, category, attitude) combination. Red tokens push the log-odds positive (towards A); blue tokens push it negative (towards B). Comparing the two force plots reveals which tokens are responsible for the position-dependent flip — tokens whose attribution changes sign between orderings are the primary drivers of the bias.
def _force_plot_to_array(exp) -> np.ndarray:
"""Render a SHAP force plot to an RGBA numpy array.
shap.plots.force(matplotlib=True) always creates its own figure,
so the only way to embed two plots on one page is to rasterise each
one and composite them with imshow.
"""
shap.plots.force(
base_value=float(exp.base_values),
shap_values=exp.values,
feature_names=list(exp.data),
matplotlib=True,
show=False,
)
fig_tmp = plt.gcf()
buf = io.BytesIO()
fig_tmp.savefig(buf, format="png", dpi=200, bbox_inches="tight", pad_inches=0.1)
plt.close(fig_tmp)
buf.seek(0)
return mpimg.imread(buf)PNG_DIR = "../images"
png_paths = []
for i, (rec, sv_ab, sv_ba) in enumerate(shap_results):
a, b = rec.company_a, rec.company_b
winner_ab, winner_ba = rec.pred_ab, rec.pred_ba
exp_ab = sv_ab[0, :, 0]
exp_ba = sv_ba[0, :, 0]
log_odds_ab = float(exp_ab.base_values) + float(exp_ab.values.sum())
log_odds_ba = float(exp_ba.base_values) + float(exp_ba.values.sum())
prompt_ab = get_user_prompt(a, b, rec.category)
prompt_ba = get_user_prompt(b, a, rec.category)
img_ab = _force_plot_to_array(exp_ab)
img_ba = _force_plot_to_array(exp_ba)
fig, axes = plt.subplots(2, 1, figsize=(16, 10))
fig.suptitle(
f"{a} vs {b} — Category: {rec.category}\n"
f"Red = supports {a} (positive) | Blue = supports {b} (negative)",
fontsize=11,
)
for ax, img, ordering, winner, prompt, log_odds in [
(axes[0], img_ab, f"{a} listed first", winner_ab, prompt_ab, log_odds_ab),
(axes[1], img_ba, f"{b} listed first", winner_ba, prompt_ba, log_odds_ba),
]:
ax.imshow(img, aspect="auto")
ax.set_axis_off()
ax.text(
0.5, 0.20,
f"{ordering} → predicts {winner}\n"
f'Prompt: "{prompt}"',
transform=ax.transAxes,
ha="center", va="top",
fontsize=9, style="italic",
)
fig.tight_layout()
png_path = f"{PNG_DIR}/shap_positional_bias_{i}.png"
fig.savefig(png_path, bbox_inches="tight", dpi=150)
png_paths.append(png_path)
plt.close(fig)
print(f"Saved {len(png_paths)} PNG(s):")
for p in png_paths:
print(f" {p}")Saved 5 PNG(s):
images/shap_positional_bias_0.png
images/shap_positional_bias_1.png
images/shap_positional_bias_2.png
images/shap_positional_bias_3.png
images/shap_positional_bias_4.pngfrom IPython.display import Image, display
for p in png_paths:
display(Image(p))