# Package versions used in this notebook:
# matplotlib==3.10.8
# numpy==2.4.4
# scikit-learn==1.8.0
# tqdm==4.67.3
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.decomposition import PCA
from sklearn.metrics.pairwise import euclidean_distances, rbf_kernel
from tqdm.notebook import tqdm
np.random.seed(42)Appendix C — MMD-Critic on MNIST
This notebook is part of the MINERVA best-practice guides and is released under the Apache License, Version 2.0. The accompanying written guide is released under CC BY 4.0.
MMD-Critic selects two complementary sets from a dataset: - Prototypes — representative examples, chosen by greedily minimising the \(\text{MMD}^2\) between the full dataset and the prototype set - Criticisms — atypical examples not well covered by the prototypes (highest \(|f(z)|\))
The \(\text{MMD}^2\) between dataset \(\mathcal{X}\) and prototype set \(\mathcal{P}\) is:
\[\text{MMD}^2(\mathcal{X}, \mathcal{P}) = \frac{1}{n^2}\sum_{x,x' \in \mathcal{X}} k(x,x') - \frac{2}{n|\mathcal{P}|}\sum_{\substack{x \in \mathcal{X} \\ p \in \mathcal{P}}} k(x,p) + \frac{1}{|\mathcal{P}|^2}\sum_{p,p' \in \mathcal{P}} k(p,p')\]
Prototype selection algorithm: 1. Start with \(\mathcal{P} = \emptyset\). 2. While \(|\mathcal{P}|\) < desired number of prototypes: - For each candidate \(z \in \mathcal{X} \setminus \mathcal{P}\), compute \(\text{MMD}^2(\mathcal{X},\, \mathcal{P} \cup \{z\})\). - Add to \(\mathcal{P}\) the point that minimises \(\text{MMD}^2\).
Criticisms are selected from \(\mathcal{X} \setminus \mathcal{P}\) as the points with the largest absolute witness function value:
\[f(z) = \frac{1}{n}\sum_{x \in \mathcal{X}} k(z,x) - \frac{1}{|\mathcal{P}|}\sum_{p \in \mathcal{P}} k(z,p)\]
Implemented from scratch with an RBF kernel applied directly to normalised pixel values. The bandwidth is set by the median heuristic \(\gamma = 1/(2\cdot\text{median}(\|x_i-x_j\|^2))\), which adapts automatically to the scale of the data without any manual tuning. A separate PCA step is used only for the t-SNE visualisation at the end.
def median_gamma(X, n_sub=1000):
"""Median heuristic: gamma = 1 / (2 * median(||xi - xj||^2)) over unique pairs."""
sub = X[np.random.choice(len(X), min(len(X), n_sub), replace=False)]
sq_dists = euclidean_distances(sub, squared=True)
median_sq = np.median(sq_dists[np.triu_indices_from(sq_dists, k=1)])
return 1.0 / (2.0 * median_sq)
def mmd_critic(X, n_prototypes, n_criticisms=0, gamma=None):
n = len(X)
if gamma is None:
gamma = median_gamma(X) # bandwidth from median of pairwise squared distances
K = rbf_kernel(X, gamma=gamma)
K_XX = K.mean() # (1/n²) Σ_{x,x'} k(x,x') — constant term of MMD²
proto_idx = []
for _ in tqdm(range(n_prototypes), desc="Selecting prototypes"):
m = len(proto_idx)
best_idx = None
best_mmd2 = np.inf
for z in range(n):
if z in proto_idx:
continue
# Compute MMD²(X, P ∪ {z}):
# (1/n²) · Σ_{x,x'} k(x,x')
# − (2/n(m+1)) · (Σ_{x,q∈P∪{z}} k(x,q))
# + (1/(m+1)²) · (Σ_{q,q'∈P∪{z}} k(q,q'))
candidate_idx = proto_idx + [z]
S_XQ = K[:, candidate_idx].sum()
S_QQ = K[np.ix_(candidate_idx, candidate_idx)].sum()
mmd2 = K_XX - 2.0 / (n * (m + 1)) * S_XQ + 1.0 / (m + 1) ** 2 * S_QQ
if mmd2 < best_mmd2:
best_mmd2 = mmd2
best_idx = z
proto_idx.append(best_idx)
proto_idx = np.array(proto_idx)
if n_criticisms == 0:
return proto_idx, np.array([], dtype=int)
# Criticisms: greedily select points with high |witness function|, suppressing
# scores of points similar to each selected criticism to ensure diversity.
col_mean = K.mean(axis=0) # (1/n) Σ_x k(x, z)
proto_sim = K[:, proto_idx].mean(axis=1) # (1/|P|) Σ_{p∈P} k(z, p)
crit_scores = np.abs(col_mean - proto_sim)
crit_scores[proto_idx] = -np.inf
crit_idx = []
for _ in range(n_criticisms):
best = int(np.argmax(crit_scores))
crit_idx.append(best)
# After selecting `best`, suppress nearby points:
# score(z) *= (1 - k(z, best))
# Points with k(z, best) ≈ 1 (similar to best) are pushed to ~0.
# Points with k(z, best) ≈ 0 (far from best) are left unchanged.
crit_scores *= (1.0 - K[:, best])
crit_scores[best] = -np.inf
return proto_idx, np.array(crit_idx)N_PROTOTYPES, N_CRITICISMS, N_PER_CLASS = 20, 5, 500
# Load MNIST, subsample, normalise to [0, 1]
mnist = fetch_openml('mnist_784', version=1, as_frame=False, parser='auto')
X_full = mnist.data.astype(np.float32) / 255.0
y_full = mnist.target.astype(int)
# Stratified subsampling: N_PER_CLASS samples per digit class
idx = np.concatenate([np.random.choice(np.where(y_full == d)[0], N_PER_CLASS, replace=False)
for d in range(10)])
X, y = X_full[idx], y_full[idx]
# Run MMD-Critic directly on normalised pixels.
proto_idx, crit_idx = mmd_critic(X.astype(np.float64), N_PROTOTYPES, N_CRITICISMS)
print(f"Prototypes — indices: {proto_idx.tolist()}, classes: {y[proto_idx].tolist()}")
print(f"Criticisms — indices: {crit_idx.tolist()}, classes: {y[crit_idx].tolist()}")Prototypes — indices: [4964, 239, 964, 4850, 198, 58, 2120, 459, 4822, 1143, 4350, 2557, 3336, 3715, 4199, 3434, 1681, 4939, 1021, 3818], classes: [9, 0, 1, 9, 0, 0, 4, 0, 9, 2, 8, 5, 6, 7, 8, 6, 3, 9, 2, 7]
Criticisms — indices: [3925, 3339, 4951, 237, 4405], classes: [7, 6, 9, 0, 8]COLS = 10
proto_rows = (N_PROTOTYPES + COLS - 1) // COLS # e.g. 2 for N_PROTOTYPES=20
total_rows = proto_rows + 1 # prototype rows + 1 criticism row
fig, axes = plt.subplots(
total_rows, COLS + 1, # +1 narrow column for section labels
figsize=((COLS + 0.5) * 1.6, total_rows * 1.8),
gridspec_kw={'width_ratios': [0.4] + [1] * COLS}
)
# ── Section labels (leftmost narrow column) ───────────────────────────────────
for row in range(total_rows):
axes[row, 0].axis('off')
axes[proto_rows // 2, 0].text(
0.5, 0.5, 'Prototypes',
transform=axes[proto_rows // 2, 0].transAxes,
fontsize=11, color='steelblue', fontweight='bold',
ha='center', va='center', rotation=90
)
axes[proto_rows, 0].text(
0.5, 0.5, 'Criticisms',
transform=axes[proto_rows, 0].transAxes,
fontsize=11, color='firebrick', fontweight='bold',
ha='center', va='center', rotation=90
)
# ── Prototypes ────────────────────────────────────────────────────────────────
for j, i in enumerate(proto_idx):
row, col = divmod(j, COLS)
ax = axes[row, col + 1]
ax.imshow(X[i].reshape(28, 28), cmap='gray_r', vmin=0, vmax=1)
ax.set_title(str(y[i]), fontsize=9, color='steelblue')
ax.axis('off')
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color('steelblue')
spine.set_linewidth(2)
# Hide unused cells in the last prototype row
for j in range(N_PROTOTYPES, proto_rows * COLS):
row, col = divmod(j, COLS)
axes[row, col + 1].axis('off')
# ── Criticisms ────────────────────────────────────────────────────────────────
for j, i in enumerate(crit_idx):
ax = axes[proto_rows, j + 1]
ax.imshow(X[i].reshape(28, 28), cmap='gray_r', vmin=0, vmax=1)
ax.set_title(str(y[i]), fontsize=9, color='firebrick')
ax.axis('off')
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color('firebrick')
spine.set_linewidth(2)
for j in range(N_CRITICISMS, COLS):
axes[proto_rows, j + 1].axis('off')
plt.suptitle('MMD-Critic — MNIST', fontsize=13, y=1.02)
plt.tight_layout()
plt.savefig("../images/mmd_critic_mnist.svg", bbox_inches="tight")
plt.show()
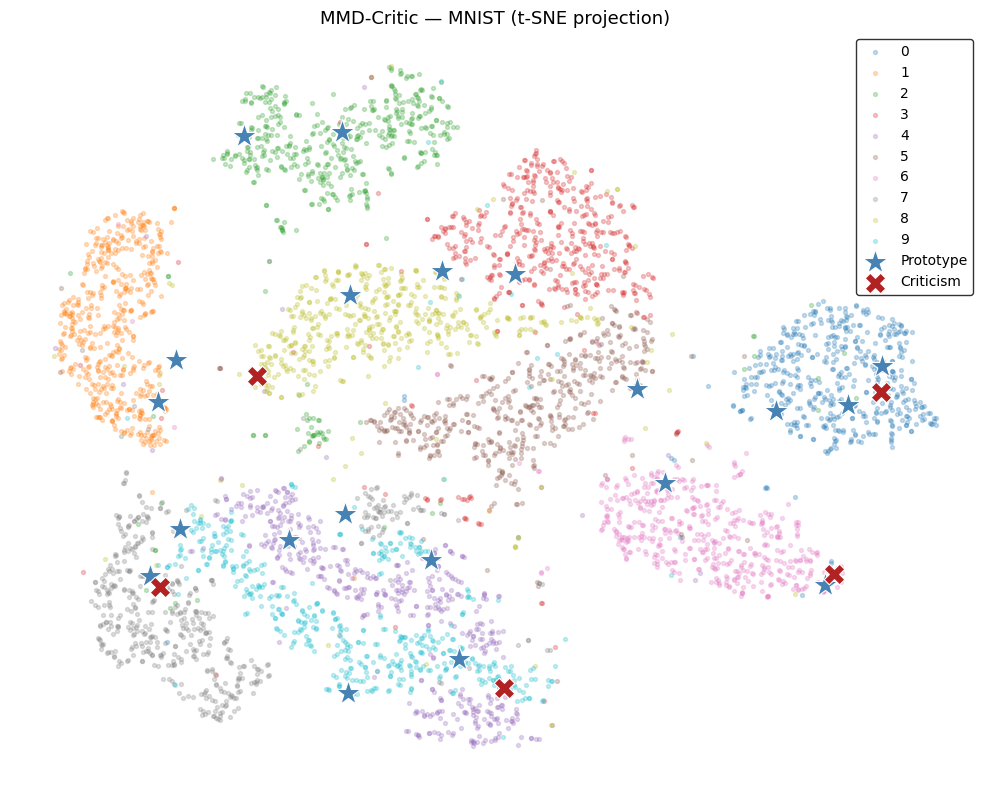
from sklearn.manifold import TSNE
# Pre-reduce to 50 dims with PCA only to speed up t-SNE (standard practice).
# This PCA is used solely for visualisation — MMD-Critic ran on raw pixels above.
X_pca_viz = PCA(n_components=50, random_state=42).fit_transform(X)
print("Computing t-SNE embedding…")
X_2d = TSNE(n_components=2, random_state=42, perplexity=30).fit_transform(X_pca_viz)
fig, ax = plt.subplots(figsize=(10, 8))
# Background: all samples coloured by digit class
palette = plt.cm.tab10(np.arange(10) / 10)
for digit in range(10):
mask = y == digit
ax.scatter(X_2d[mask, 0], X_2d[mask, 1],
color=palette[digit], alpha=0.25, s=8,
label=str(digit), rasterized=True)
# Prototypes — blue stars
ax.scatter(X_2d[proto_idx, 0], X_2d[proto_idx, 1],
marker='*', s=350, color='steelblue', edgecolors='white',
linewidths=0.8, zorder=5, label='Prototype')
# Criticisms — red crosses
ax.scatter(X_2d[crit_idx, 0], X_2d[crit_idx, 1],
marker='X', s=220, color='firebrick', edgecolors='white',
linewidths=0.8, zorder=5, label='Criticism')
ax.legend(ncol=4, fontsize=9, framealpha=0.9,
loc='lower center', bbox_to_anchor=(0.5, -0.04))
ax.legend().get_frame().set_edgecolor('black')
ax.set_title('MMD-Critic — MNIST (t-SNE projection)', fontsize=13)
ax.set_axis_off()
plt.tight_layout()
plt.savefig("../images/mmd_critic_mnist_tsne.svg", bbox_inches="tight")
plt.show()Computing t-SNE embedding…