flowchart TD
id1(Training Complete) --> id2(Checkpoint Saved);
id2 --> id3(Quick Eval on Core Benchmarks);
id3 --> id4{{Pass Quick Thresholds?}};
id4 -->|Yes| id5(Full Eval on Complete Suite);
id4 -->|No| id6(Alert and Debug);
id5 --> id7(LLM Judge Evaluation);
id7 --> id8(Human Review);
id8 --> id9{{Pass Human Review?}};
id9 -->|Yes| id10(Deploy);
id9 -->|No| id11(Reject and Debug);
4 Post-Training — Alignment and User-Centered Objectives
4.1 Instruction Tuning
Once a large language model (LLM) has completed its pre-training phase—having learned broad patterns, syntactic structures, and semantic relationships from vast amounts of text data—it possesses impressive general knowledge and language understanding capabilities. However, pre-trained models are not yet optimized for specific downstream tasks or user interactions. They can predict the next token in a sequence with remarkable accuracy, but they may struggle to follow instructions, engage in meaningful dialogue, or adhere to desired behavioral patterns.
This gap between general language modeling and practical utility is where post-training becomes essential. This procedure is also called fine-tuning due to the fact that model weights undergo significantly smaller changes compared to pre-training, transforming raw next-token predictors into specialized, user-friendly AI assistants that can understand and execute complex instructions, provide helpful responses, and adapt to domain-specific knowledge.
The Post-training Landscape
Post-training encompasses several key approaches, each addressing different aspects of model refinement:
Instruction Tuning: Teaching models to follow explicit instructions and perform specific tasks through supervised learning on carefully curated instruction-response pairs.
Reinforcement Learning: Using feedback signals (including but not limited to human preferences) to optimize model behavior, training on ranked responses to improve characteristics such as helpfulness, harmlessness, honesty, reasoning, and output quality.
Additionally, once a model is instruction-tuned and aligned, further optimization techniques can be applied to enhance its performance in production environments:
- Efficient Inference Optimization: Adapting models for production deployment by reducing latency, optimizing resource utilization, and improving time-to-completion metrics without sacrificing quality.
The Foundation: Instruction Tuning
Instruction Tuning serves as the cornerstone refinement after the pre-training phase. The instruction tuning process involves training a foundational model on a dataset of instruction-following examples, where each example consists of an instruction (or prompt) paired with the desired response. For this reason, it is also known as supervised fine-tuning (SFT). Through this supervised learning approach, the model learns to:
- Interpret and follow diverse instructions accurately.
- Maintain consistency in response format and style.
- Generalize across different task types and domains.
- Respond appropriately to various levels of complexity and specificity.
- Align with human ethical values, i.e., follow safety and fairness guardrails.
Unlike traditional fine-tuning for specific tasks (such as classification or named entity recognition), instruction tuning aims to create versatile models capable of handling a wide array of tasks through natural language instructions alone. This flexibility makes instruction-tuned models particularly valuable for applications requiring multi-task capabilities without task-specific model variants.
Importance of Instruction Tuning
Foundational LLMs trained on vast amounts of data can be prompted to perform a range of natural language tasks. They are good at confidently predicting the next token, though they often fall into pitfalls of unintended behavior such as making up facts (commonly known as “hallucinations”), generating biased or inappropriate text, or simply not following user instructions. Avoiding such unwanted behavior is essential for trustworthy use in scientific and industry workflows.
There is a clear need to align language models to adhere to the user’s intentions and instructions. Instruction fine-tuning addresses this need by supervising a pre-trained model on carefully curated instruction–response pairs. Rather than merely predicting the next token in a vacuum, the model is taught to interpret an instruction, structure a solution, and produce outputs that respect constraints such as tone, format, length, citations, or safety policies.
Key benefits in practice include:
- Steerability and consistency: the model follows task descriptions and formatting reliably across prompts and sessions.
- Policy and safety adherence: it learns when to refuse, how to de-escalate risky requests, and how to minimize biased or harmful content within defined guidelines.
- Domain and multilingual adaptation: data reflecting specific European domains and languages (e.g., de, fr, it, es, nl, el, etc.) improves relevance and accessibility.
- Factuality and robustness: with high-quality, grounded examples and evaluation loops, the propensity for hallucinations decreases and answers become better calibrated.
- Operational efficiency: compared to pre-training or full RL pipelines, SFT can be made compute-efficient; with parameter-efficient methods (e.g., LoRA/QLoRA) it becomes feasible on modest multi-GPU nodes common across European HPC centers.
In short, instruction fine-tuning turns a capable but generic language model into a helpful, reliable assistant that aligns with user intent and organizational policies.
What’s Ahead
In the following sections, we will dive deep into the theory and practice of instruction tuning:
- Dataset preparation strategies (Instruction Datasets) for creating high-quality instruction-response pairs.
- Training methodologies (Training Techniques) including full fine-tuning, parameter-efficient approaches (LoRA, QLoRA), and hybrid techniques.
- Evaluation frameworks (Evaluation) for assessing instruction-following capabilities and model alignment.
- Best practices (Summary and Best Practices) for scaling instruction tuning across multi-node, multi-GPU environments.
By mastering instruction tuning, you’ll establish the foundation for creating AI models that are not only powerful but also controllable, useful, and aligned with the specific needs of your applications and users.
4.1.1 Instruction Datasets
Instruction datasets are collections of input-output pairs and include examples designed to teach a language model to follow specific instructions. These examples most commonly come in the form of a user instruction, sometimes combined with a context, and the expected response. Sometimes, a sample may include multiple turns of dialogue, or even a reasoning trace that shows the intermediate steps to reach the final answer. The quality and diversity of instruction datasets are crucial for effective fine-tuning, as they directly influence the model’s ability to generalize and follow instructions in real-world applications.
Dataset Collection Techniques
As surveyed in Zhang et al. (2026), we can separate the ways of creating an instruction dataset into three generalized categories:
- Human-crafted Datasets.
- Synthetic Datasets via Distillation.
- Synthetic Datasets via Self-improvement.
Human-crafted Datasets
Human annotators write both the instructions and the target responses (often with review/rating). These datasets are high-signal and diverse, but costly to scale; they typically set strong behavioral norms and safety baselines. Some notable examples are:
- OpenAssistant Conversations (OASST-1): multilingual, multi-turn assistant conversations written and rated by volunteers; permissive licensing for research and development (see Köpf et al. (2023)).
- Dolly 15k: human-generated instruction–response pairs covering categories from InstructGPT (see Conover et al. (2023)).
- LIMA: 1000 carefully curated prompt–response pairs showing strong alignment from minimal, high-quality SFT (see Zhou et al. (2023)).
- Aya Collection: One of the biggest human collected multilingual dataset collections (see Singh et al. (2024)).
⚠️ At this point, it is necessary to recognize that dataset references included above and further in this chapter, are susceptible to deprecation by the time reader reads this document. We encourage the reader to verify their validity and be vigilant of newer and more updated datasets.
Synthetic Datasets via Distillation
Data are generated by prompting a highly capable “teacher” model, usually already fine-tuned, and recording its responses, transferring capabilities and style to the target model. These datasets are easier to scale since they allow taking outdated/low-quality data and repurposing it with high quality generated responses. However, they can inherit biases and errors from the teacher (L. Chen et al. (2024)). Moreover, licensing and usage constraints of teacher outputs should be carefully considered. Some notable examples are:
- UltraChat-200k-ShareGPT-clean: a collection of user conversations with ChatGPT shared by the users themselves (see May et al. (2024)).
- OpenOrca: distills GPT‑4/3.5 reasoning traces on instruction tasks to augment FLAN-style data, emphasizing step-by-step rationales (see Lian et al. (2023)).
- WizardLM / Evol‑Instruct: algorithmically “evolves” instructions to increase complexity and coverage, then trains on the generated data (see Xu et al. (2023)).
- Alpaca: A dataset introduced by the Stanford NLP Group comprised by 52K pieces of distillation data produced by GPT-3 and Llama-7B (see Taori et al. (2023)).
Synthetic Datasets via Self-improvement
A pre-trained foundational model (or a weaker assistant) bootstraps new instructions and answers from a small human-created set of examples acting as seed. The model itself, inspired by the seed examples, generates new instruction-context-responses pairs over iterations, employing filtering, rejection, or instruction “evolution” to improve breadth and difficulty. These datasets can be scaled with less human effort, since both queries and responses are auto-generated. On the other hand, generated pairs require careful quality control to avoid drift and overfitting to model’s existing biases and limitations. Some notable examples are:
- Self-Instruct: pipeline to auto-generate instruction–input–output triplets and filter them for SFT (see Wang et al. (2023)).
- SPIN: a variant self-improvement approach enabling language models to improve without additional human data or feedback from bigger language models. (see Z. Chen et al. (2024)).
Chat Templates and Prompt Formatting
Chat templates define the structured format that transforms raw instruction-response pairs into the token sequences a model actually sees during training and inference. Getting this right is critical: a mismatch between training and serving templates is one of the most common causes of degraded instruction-following behavior.
Why Chat Templates Matter
Pre-trained models have no inherent understanding of conversational roles or turn boundaries. Chat templates impose this structure by:
- Delimiting roles: Clearly marking where user input ends and where the assistant should respond.
- Enabling system prompts: Injecting persistent behavioral instructions (persona, safety rules, output format) that apply across turns.
- Supporting multi-turn context: Preserving conversation history so the model can reference prior exchanges.
- Signaling special behaviors: Using tokens like
<think>or<tool_call>to trigger reasoning traces or tool use.
Without consistent templates, a model may hallucinate role boundaries, ignore system instructions, or produce malformed outputs.
Common Chat Template Formats
Different model families use different conventions. The most widely adopted formats include:
Mistral Format:
<s>[INST] You are a helpful assistant. [/INST] Hi! How can I help you today?</s> [INST] What is the capital of France? [/INST] The capital of France is ParisChatML (OpenAI-style): used by GPT models and adopted by many open-weight models (Qwen, SmolLM2, etc.).
<|im_start|>system You are a helpful assistant.<|im_end|> <|im_start|>user What is the capital of France?<|im_end|> <|im_start|>assistant The capital of France is Paris.<|im_end|>Llama 2 Chat Format: uses
[INST]and<<SYS>>markers.<s>[INST] <<SYS>> You are a helpful assistant. <</SYS>> What is the capital of France? [/INST] The capital of France is Paris. </s>Llama 3 Chat Format: uses
<|begin_of_text|>,<|start_header_id|>{role}<|end_header_id|>and<|eot_id|>markers.<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|> What is the capital of France?<|eot_id|><|start_header_id|>assistant<|end_header_id|> The capital of France is Paris.<|eot_id|>Alpaca Format: a simpler instruction-focused template without explicit multi-turn support.
### Instruction: What is the capital of France? ### Response: The capital of France is Paris.Vicuna/ShareGPT Format: uses natural language role markers.
USER: What is the capital of France? ASSISTANT: The capital of France is Paris.
Key Structural Components
A well-designed chat template includes:
| Component | Purpose | Example |
|---|---|---|
| System prompt | Sets persistent behavioral context (persona, constraints, safety rules) | “You are a helpful coding assistant. Always include comments.” |
| Role markers | Delimit speaker turns (user, assistant, system) |
<\|im_start\|>user, [INST], USER: |
| Turn delimiters | Signal end of a turn and enable attention masking | <\|im_end\|>, </s>, [/INST] |
| Special tokens | Trigger specific behaviors (reasoning, tool calls) | <think>, <tool_call>, <\|python_tag\|> |
Multi-turn Conversations
Real-world instruction tuning often involves multi-turn dialogues. The template must preserve conversation history while clearly delimiting each exchange. For example, using the ChatML format would look something like:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is the capital of France?<|im_end|>
<|im_start|>assistant
The capital of France is Paris.<|im_end|>
<|im_start|>user
What is its population?<|im_end|>
<|im_start|>assistant
Paris has a population of approximately 2.1 million in the city proper,
and about 12 million in the metropolitan area.<|im_end|>During training, loss is typically computed only on assistant turns (see “Loss Masking” below), while user and system tokens provide context.
Applying Templates in Practice
Chat templates are defined as part of the tokenizer configuration, ensuring consistent application across training and inference. They are usually written as jinja-style templates with placeholders for roles and content, which render a list of messages into a single formatted string . E.g., following the ChatML format, the template would look like this:
{%- for message in messages -%}
{%- if message.role == "system" -%}
<|im_start|>system
{{ message.content }}<|im_end|>
{%- elif message.role == "user" -%}
<|im_start|>user
{{ message.content }}<|im_end|>
{%- elif message.role == "assistant" -%}
<|im_start|>assistant
{{ message.content }}<|im_end|>
{%- endif -%}
{%- endfor -%}In the widely adopted python library transformers, developed and maintained by HuggingFace, most tokenizers ship with a built-in chat template accessible via the apply_chat_template() method. In the following simple example, it is demonstrated how to prepare our raw text dataset before feeding it to our instruction fine-tuning pipeline:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
]
# Returns the formatted string (for inspection)
formatted = tokenizer.apply_chat_template(messages, tokenize=False)
print(formatted)
# Returns token IDs ready for the model
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt")For training, ensure the same template is used across dataset preparation, training, and inference. Make sure to store the template configuration alongside checkpoints.
# After training
model.save_pretrained("checkpoint-dir")
tokenizer.save_pretrained("checkpoint-dir") # Saves chat_template in tokenizer_config.jsonTemplate Mismatch Pitfalls
Common failure modes when templates are inconsistent:
- Training vs. inference mismatch: The model expects
<|im_start|>but receives[INST]—outputs become incoherent or the model fails to stop generating. - Missing special tokens: If special tokens weren’t added to the tokenizer during training, they become unknown tokens at inference.
- System prompt drift: Training without system prompts but deploying with them (or vice versa) degrades instruction adherence.
- Truncation errors: Long conversations truncated mid-turn break role boundaries.
💡 Best practice: Always validate that
tokenizer.chat_templatematches what was used during training, or explicitly set it when loading.
Special Tokens for Reasoning and Tool Use
Modern instruction-tuned models increasingly use structured tokens to enable advanced capabilities:
Reasoning tokens (
<think>,</think>): Wrap chain-of-thought reasoning that may or may not be shown to users. Models like DeepSeek-R1 and Qwen-QwQ use these to separate internal reasoning from final answers.<|im_start|>assistant <think> The user is asking about population. I should provide both city proper and metropolitan figures for completeness. </think> Paris has a population of approximately 2.1 million...<|im_end|>Tool-calling tokens (
<tool_call>,<|python_tag|>): Signal that the model is invoking an external tool or generating executable code.
❗ Note: When training with these tokens, ensure they are added to the tokenizer vocabulary and that your training data consistently uses them.
Reasoning Datasets
Reasoning datasets are instruction-tuning datasets that include explicit step-by-step reasoning traces in the target responses. Unlike standard instruction datasets where the model outputs a direct answer, reasoning datasets teach the model to “show its work”, decomposing complex problems into intermediate steps before arriving at a final answer (Wei et al. (2022)).
Why Reasoning Data Matters
Language models have proven to unlock unprecedented abilities, like in-context learning, role playing or analogical reasoning. And this only on inference time and based on the training data the model has seen.
Among these abilities, human-like reasoning has garnered significant attention from both academia and industry, since it demonstrates great potential for LLMs to generalize to complex real-world problems through abstract and logical reasoning.
Training on reasoning traces provides several benefits:
- Improved accuracy on complex tasks: Models learn to break down multi-step problems rather than attempting single-shot answers, reducing errors on math, logic, and multi-hop reasoning tasks.
- Better calibration: The explicit reasoning process helps models recognize when they lack sufficient information or when a problem is ambiguous.
- Interpretability: Step-by-step outputs allow users (and evaluators) to identify where errors occur and assess the validity of the model’s logic.
- Generalization: Reasoning patterns learned on one domain (e.g., arithmetic) can transfer to related domains (e.g., algebraic reasoning).
Types of Reasoning
Sequential/Linear Reasoning Path
Chain-of-Thought (CoT) (Wei et al. (2022))
The most widespread method of implementing reasoning logic in LLMs is Chain-of-Thought prompting. By following a sequential path of the “think step-by-step” paradigm, CoT bridges the gap between the question and its solution. The model generates intermediate reasoning steps before producing a final answer, mimicking human problem-solving processes. CoT can be elicited through few-shot examples containing reasoning traces or simply by appending “Let’s think step by step” to the prompt (zero-shot CoT).
Branching Reasoning Paths
Tree-of-Thoughts (ToT) (Yao et al. (2023))
For complex problems like coding a whole application or solving a Sudoku puzzle, a linear path is often insufficient. Tree-of-Thoughts allows the model to explore multiple “branches” of reasoning simultaneously, enabling systematic exploration of different solution strategies. ToT maintains a tree structure where each node represents a partial solution, and the model can evaluate, expand, or backtrack from nodes using search algorithms like breadth-first or depth-first search. This approach excels at problems requiring planning, lookahead, or exploration of multiple hypotheses.
Graph-of-Thoughts (GoT) (Besta et al. (2024))
Graph-of-Thoughts extends the ToT paradigm by modeling LLM reasoning as an arbitrary graph rather than a tree. In GoT, units of information (“thoughts”) are vertices, and edges represent dependencies between them. This enables combining arbitrary thoughts into synergistic outcomes, distilling networks of reasoning, or refining thoughts through feedback loops. GoT has shown improvements over ToT on tasks like sorting (62% quality improvement) while reducing computational costs by over 31%. The graph structure more closely mirrors human cognitive processes, which often involve recurrence and non-linear connections between ideas.
ReAct (Reasoning + Acting) (Yao et al. (2022))
ReAct synergizes reasoning and acting by interleaving chain-of-thought reasoning with task-specific actions. The model generates reasoning traces to plan and track progress, while actions allow it to interface with external environments—such as knowledge bases, APIs, or tools—to gather additional information. This interleaved approach overcomes hallucination issues prevalent in pure reasoning by grounding the model’s thoughts in real-world observations. ReAct has demonstrated strong performance on question answering (HotpotQA), fact verification (Fever), and interactive decision-making benchmarks (ALFWorld, WebShop), producing human-interpretable task-solving trajectories.
Decomposition-based Reasoning
Least-to-Most Prompting (Zhou et al. (2022))
Least-to-Most prompting addresses the challenge of easy-to-hard generalization, where standard CoT struggles with problems harder than the exemplars in the prompt. The strategy decomposes a complex problem into a series of simpler sub-problems, then solves them in sequence—where each subproblem solution builds on previous answers. This approach achieves remarkable generalization: using just 14 exemplars, it solved the SCAN compositional generalization benchmark with 99%+ accuracy across all splits, compared to 16% for standard CoT. The method is particularly effective for symbolic manipulation, compositional tasks, and multi-step mathematical reasoning.
Algorithm-of-Thoughts (AoT) (Sel et al. (2023))
Algorithm-of-Thoughts propels LLMs through algorithmic reasoning pathways entirely in-context, without requiring external tree search or multiple queries. By embedding algorithmic search patterns (like DFS or BFS) directly into the prompt, AoT exploits the recurrence dynamics of LLMs to expand idea exploration using merely one or a few queries. This approach outperforms earlier single-query methods and even multi-query strategies that employ extensive tree search, while using significantly fewer tokens. Intriguingly, instructing an LLM with an algorithm can lead to performance surpassing the algorithm itself, suggesting LLMs can weave intuition into optimized search procedures.
General rule: Reasoning approaches exist along a spectrum of trade-offs between simplicity and capability. Linear methods like Chain-of-Thought are intuitive and practical, generally considered the default unless particular considerations come into play; tree and graph-based methods unlock systematic problem-solving and handle planning-intensive tasks, but at higher computational cost; finally, specialized decomposition approaches (Least-to-Most, AoT) achieve the strongest performance for narrow problem classes when you invest in careful prompt engineering and custom design. Your choice should balance your tolerance for implementation complexity and inference overhead against the specific demands and difficulty of your target problems.
Types of Reasoning Datasets
Reasoning datasets typically target one or more of the following:
| Type | Description | Example Task |
|---|---|---|
| Mathematical | Arithmetic, algebra, word problems, proofs | “A train travels 60 km/h for 2 hours, then 80 km/h for 1.5 hours. What is the total distance?” |
| Logical | Deduction, constraint satisfaction, syllogisms | “All mammals are warm-blooded. Whales are mammals. Are whales warm-blooded?” |
| Commonsense | World knowledge, physical intuition, social reasoning | “Why would someone bring an umbrella on a cloudy day?” |
| Multi-hop | Combining information from multiple sources | “Who was president when the company that made the iPhone was founded?” |
| Code reasoning | Algorithmic thinking, debugging, complexity analysis | “What does this function return for input [3, 1, 4, 1, 5]?” |
Notable Open-source Reasoning Datasets
| Dataset | Domain | Size | Format | License |
|---|---|---|---|---|
| OpenMathInstruct-2 | Math (GSM8K/MATH-style) | 14M problems | CoT solutions | Llama 3.1 Community |
| OpenCodeReasoning | Code + reasoning | 736K samples | Reasoning traces + code | Apache 2.0 |
| DeepMath-103K | Advanced math | 103K problems | Long CoT traces | Apache 2.0 |
| MetaMathQA | Math reasoning | 395K examples | Augmented CoT | MIT |
| Orca-Math | Math word problems | 200K problems | Detailed solutions | MIT |
| CAMEL-AI Math | Math dialogues | 50K conversations | Multi-turn CoT | CC BY-NC 4.0 |
Formatting Reasoning Traces
When preparing reasoning data for instruction tuning, the structure of the reasoning trace significantly impacts learning. Common approaches include:
Inline reasoning (reasoning embedded in the response)
### Instruction:
A store sells apples for €2 each. If Maria buys 5 apples and pays with a €20 note, how much change does she receive?
### Response:
Let me solve this step by step.
First, I need to calculate the total cost of the apples:
- Cost per apple: €2
- Number of apples: 5
- Total cost: €2 × 5 = €10
Next, I calculate the change:
- Amount paid: €20
- Total cost: €10
- Change: €20 - €10 = €10
Maria receives €10 in change.Tagged reasoning (using special tokens to delimit thinking)
<|im_start|>user
A store sells apples for €2 each. If Maria buys 5 apples and pays with a €20 note, how much change does she receive?<|im_end|>
<|im_start|>assistant
<think>
I need to calculate:
1. Total cost = €2 × 5 = €10
2. Change = €20 - €10 = €10
</think>
Maria receives €10 in change.<|im_end|>The tagged approach allows filtering or hiding reasoning at inference time, which can be useful when users prefer concise answers while the model still benefits from internal deliberation.
Trade-offs and Considerations
- Verbosity vs. efficiency: Reasoning traces increase output length, raising inference costs due to the generation of additional tokens. For latency-sensitive applications, consider training separate models or using tagged reasoning that can be hidden.
- Quality over quantity: A smaller dataset with high-quality, verified reasoning traces often outperforms larger datasets with noisy or incorrect chains. Prefer datasets with human verification or strong filtering.
- Domain transfer: Models trained heavily on math reasoning may not automatically gain commonsense reasoning abilities. Mix reasoning data across domains for broader capabilities.
- Avoiding shortcuts: Some models learn to mimic reasoning patterns without genuine understanding. Validate with held-out problems that require novel reasoning steps.
Tool-calling Datasets
Tool-calling (or function-calling) datasets train language models to interpret natural language instructions and generate structured API calls. These datasets are essential for building AI agents that can interact with external tools, databases, and services—transforming LLMs from passive text generators into active systems capable of executing tasks in the real world (e.g., searching the internet).
Why Tool-calling Matters
Function-calling agents bridge the gap between natural language understanding and programmatic action. When a user asks “What’s the weather in Paris today?”, a function-calling model can:
- Recognize that a tool is needed
- Select the appropriate function (e.g.,
get_weather) - Extract and format the required arguments (e.g.,
{"location": "Paris", "date": "today"}) - Return the structured call for execution
This capability enables applications such as:
- Autonomous agents: Systems that plan and execute multi-step tasks using various APIs.
- Enterprise workflows: Automated data retrieval, CRM updates, and report generation.
- Digital assistants: Booking flights, managing calendars, controlling smart devices.
- Code generation: Executing database queries, calling libraries, interacting with external services.
Dataset Structure and Format
Tool-calling datasets typically include three components:
| Component | Description | Example |
|---|---|---|
| User query | Natural language instruction | “Find flights from London to Berlin next Monday” |
| Tool definitions | JSON schemas describing available functions and parameters (usually in the system prompt) | {"name": "search_flights", "parameters": {"origin": "string", "destination": "string", "date": "string"}} |
| Expected output | The correct function call(s) with arguments | {"name": "search_flights", "arguments": {"origin": "London", "destination": "Berlin", "date": "2024-03-18"}} |
Advanced datasets also include:
- Tool responses: Simulated API outputs for training multi-turn interactions.
- Multi-tool scenarios: Queries requiring parallel or sequential calls to multiple functions.
- Irrelevance detection: Cases where no function should be invoked.
Notable Open-source Tool-calling Datasets
| Dataset | Size | Description | License |
|---|---|---|---|
| Hermes Function-calling v1 | ~11.5K | Multi-turn function calling, JSON mode, and structured extraction samples using ChatML format with <tool_call> tags |
Apache 2.0 |
| xLAM Function-calling 60k | 60K | Verified function-calling data across 21 categories and 3,673 executable APIs, generated via APIGen pipeline | CC BY 4.0 |
| Glaive Function-calling v2 | ~113K | Large-scale synthetic function-calling conversations | Apache 2.0 |
| ToolBench (Qin et al. (2023)) | 126K+ | Real-world RESTful APIs from RapidAPI spanning 49 categories, with multi-tool and single-tool scenarios | Apache 2.0 |
Example: Hermes Function-calling Format
The Hermes dataset uses a structured format with XML-style tool tags:
<|im_start|>system
You are a function calling AI model.
You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query.
<tools>
[{"type": "function", "function": {"name": "get_stock_fundamentals", "description": "Get fundamental data for a given stock symbol.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}}]
</tools>
For each function call return a json object with function name and arguments within <tool_call></tool_call> tags.<|im_end|>
<|im_start|>user
Fetch the stock fundamentals data for Tesla (TSLA)<|im_end|>
<|im_start|>assistant
<tool_call>
{"name": "get_stock_fundamentals", "arguments": {"symbol": "TSLA"}}
</tool_call><|im_end|>
<|im_start|>tool
<tool_response>
{"name": "get_stock_fundamentals", "content": {"symbol": "TSLA", "company_name": "Tesla, Inc.", "sector": "Consumer Cyclical", "market_cap": 611384164352, "pe_ratio": 49.60}}
</tool_response><|im_end|>
<|im_start|>assistant
The stock fundamentals data for Tesla (TSLA) shows:
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Market Capitalization**: $611.4B
- **P/E Ratio**: 49.60<|im_end|>Example: APIGen/xLAM Format
The xLAM dataset uses a simpler query-tools-answers structure:
{
"query": "Find the sum of all multiples of 3 and 5 between 1 and 1000, and the product of the first five prime numbers.",
"tools": [
{
"name": "math_toolkit.sum_of_multiples",
"description": "Find the sum of all multiples of specified numbers within a range.",
"parameters": {
"lower_limit": {"type": "int", "required": true},
"upper_limit": {"type": "int", "required": true},
"multiples": {"type": "list", "required": true}
}
},
{
"name": "math_toolkit.product_of_primes",
"description": "Find the product of the first n prime numbers.",
"parameters": {
"count": {"type": "int", "required": true}
}
}
],
"answers": [
{"name": "math_toolkit.sum_of_multiples", "arguments": {"lower_limit": 1, "upper_limit": 1000, "multiples": [3, 5]}},
{"name": "math_toolkit.product_of_primes", "arguments": {"count": 5}}
]
}Key Considerations for Tool-calling Data
- Verification matters: Datasets like xLAM use three-stage verification (format checking, actual execution, semantic verification) to ensure correctness. Human evaluation of xLAM showed >95% accuracy.
- Coverage of scenarios: Effective training requires diverse scenarios—single function, multiple function (selecting one from many), parallel calls, and multi-turn interactions.
- Irrelevance detection: Models must learn when not to call a function. Include examples where no tool matches the user query.
- Real vs. synthetic APIs: Real-world APIs (like those from RapidAPI in ToolBench) provide realistic complexity, while synthetic APIs allow controlled diversity.
- Multi-turn complexity: Advanced datasets include scenarios with missing parameters, long context, and composite challenges requiring multiple exchanges.
Building a Conversational Dataset: A Practical Workflow
Understanding the landscape of dataset categories is a necessary prerequisite, but translating that knowledge into a training-ready conversational dataset requires a concrete, repeatable process. The following workflow covers the practical steps—from raw material collection to quality-verified data—and includes guidance on how to blend human-authored and model-generated content at each stage.
Step 1: Clarify the Objective
Before writing or generating a single example, precisely define what the fine-tuned model must accomplish. Key dimensions to agree on upfront include:
- Target audience: Is this model serving end-users, internal teams, or developers?
- Task scope: Should the model handle customer queries, assist with code generation, answer domain-specific questions, or perform complex multi-step reasoning?
- Behavioral constraints: Which topics or response styles should the model avoid? Are there regulatory or policy requirements—for instance, EU AI Act obligations that mandate specific transparency or safety behaviors?
Clear, documented objectives prevent data drift: the gradual divergence between collected examples and the model’s intended deployment behavior.
Step 2: Gather Source Material
Raw conversational data can be derived from a range of sources depending on the application domain:
- Operational logs: customer support chat transcripts, help-desk ticket histories, or internal email threads.
- Structured knowledge bases: FAQs, product documentation, technical manuals, or policy handbooks.
- Community-contributed dialogues: openly licensed datasets such as OASST-1 or Dolly-15k provide human-written conversation pairs that can seed or supplement domain-specific collections.
- Synthetically generated prompts and responses: a capable teacher model can produce responses to seed prompts that cover topics underrepresented in available human data.
At this stage, rigorous privacy filtering is mandatory. Strip or pseudo-anonymize all personally identifiable information (PII), anonymize user and agent references, and verify compliance with applicable data regulations— GDPR in the EU context—before any further processing.
Step 3: Structure the Data
Raw text rarely arrives in a training-ready form. Normalizing it into a consistent format is an essential preparatory step. The most widely adopted structure for conversational data is the multi-turn chat format:
{
"messages": [
{"role": "system", "content": "You are a helpful technical support assistant."},
{"role": "user", "content": "My VPN connection keeps dropping after a few minutes."},
{"role": "assistant", "content": "This is often caused by idle-timeout settings on the server side.
Try enabling keep-alive packets in your VPN client configuration
(e.g., setting the keep-alive interval to 20 seconds) and verify
that the server's session timeout exceeds your expected session length."}
]
}Key normalization steps:
- Remove boilerplate, system-generated artifacts, and any metadata not relevant to the dialogue.
- Standardize encoding, punctuation conventions, and whitespace.
- Segment multi-turn conversations into coherent context windows, preserving turn order and any system prompt that governs the assistant’s persona or scope.
Step 4: Annotate and Label
Human annotation substantially improves signal quality and downstream alignment. Labeling tasks commonly applied at this stage include:
- Intent tagging: marking what the user is attempting to accomplish in each turn.
- Response quality scoring: ranking or rating candidate responses by helpfulness, accuracy, and appropriateness of tone.
- Safety labeling: flagging responses that contain harmful, misleading, or policy-violating content.
- Sentiment annotation: tracking user satisfaction across turns to identify how the model handles complaints, corrections, or frustrated users.
Well-annotated examples improve fine-tuning outcomes directly, and the preference signal they encode is also valuable as input for later RLHF or DPO (Rafailov et al. (2023)) alignment stages.
Step 5: Validate Dataset Quality
Quality validation should be completed before initiating any training run. Recommended checks include:
- Consistency checks: verify that system prompt, user intent, and assistant response form a coherent unit within each example.
- Bias audit: review a representative sample for demographic, cultural, or linguistic imbalances that could cause skewed model behavior; automated classifiers can assist but should not replace expert review.
- Coverage analysis: confirm that the distribution of topics, query types, and difficulty levels aligns with the intended deployment scope.
- Factuality verification: for factual domains, cross-reference a sample of assistant responses against authoritative sources and flag or correct errors before they are learned.
Mixing Human-crafted and Machine-generated Examples
Neither human-authored nor synthetically generated data alone produces an optimal dataset. Human examples provide high-signal behavioral anchors—they capture nuanced language, edge cases, and policy-critical interactions accurately—but are expensive and slow to produce at scale. Synthetic examples generated by a capable teacher model offer breadth and volume, but may introduce stylistic inconsistencies, factual drift, or systematic blind spots inherited from the generating model.
Blending the two sources in a deliberate, controlled manner is therefore standard practice.
| Component | Typical Share | Purpose |
|---|---|---|
| Human-crafted core | 10–30% | Policy baselines, safety demonstrations, domain ground truth |
| Human-reviewed synthetic | 10–20% | Bridging examples: machine-generated but annotator-verified |
| Synthetic (distillation-based) | 50–70% | Scaling topic coverage and instruction variety |
Recommended blending procedure
Define the human core first. Write or curate the examples that encode non-negotiable behaviors: safety refusals, brand voice, sensitive-topic handling, and high-stakes factual responses. This set should be kept small but rigorously reviewed with documented annotation guidelines and inter-annotator agreement checks.
Generate synthetic data to fill coverage gaps. Use a teacher model to produce instruction–response pairs for topics underrepresented in the human core, or to diversify phrasing, complexity levels, and language variants. Techniques such as Evol-Instruct or Self-Instruct (see Dataset Collection Techniques) can automate coverage expansion at scale.
Filter synthetic examples before merging. Apply quality gates to all machine-generated content: reward-model scoring, perplexity thresholding, or a lightweight classifier trained on the human-approved examples works well in practice. Discard outputs that are factually incorrect, stylistically inconsistent, or that violate safety guidelines.
Blend with controlled ratios. Merge the filtered synthetic examples at a ratio that ensures the human core remains statistically prominent. This is commonly achieved by up-sampling human examples or applying per-source loss weights during training, so the model internalizes human-authored norms more strongly.
Conduct a final joint audit. After merging, re-sample the combined dataset and perform a holistic review. Confirm that synthetic additions have not diluted style consistency or introduced new biases absent from the original human core.
Note: The optimal human-to-synthetic ratio is task- and model-dependent. A narrow, high-stakes deployment (e.g., medical information, legal guidance) may warrant a far higher human fraction than a general-purpose assistant. Where resources permit, run ablation experiments with different ratios and compare downstream evaluation scores before committing to a final mixture.
Dataset Quality Best Practices
- Diversity over repetition: include a range of query complexity levels—from simple single-turn questions to extended multi-turn, multi-step dialogues. Models trained on repetitive patterns overfit quickly and produce rigid, formulaic responses in production.
- Balance conversation length: a healthy dataset contains both brief transactional exchanges and longer problem-solving dialogues. Homogeneous length distributions lead to poor generalization across real-world interaction styles.
- Cover edge cases deliberately: include ambiguous or under-specified queries, negative user feedback, implicit follow-up questions, and adversarially phrased inputs. Models that have never encountered these patterns in training will handle them poorly at inference time.
- Human-in-the-loop at key gates: even in predominantly synthetic pipelines, human reviewers should validate the human core, spot-check a sample of filtered synthetics, and formally sign off on the final mixture before each training run.
4.1.2 Training Techniques
This section surveys the practical methods used to turn a pre-trained LLM into an instruction-following system. The goal is to balance alignment quality, compute cost, and iteration speed. Below we describe common approaches, recommended recipes, tooling, and hardware-specific caveats.
Training Contracts and Success Criteria
Before starting an instruction tuning run, clearly define inputs, expected outputs, and success metrics. This “training contract” helps avoid wasted compute and ensures reproducibility.
Inputs
| Component | Description | Example |
|---|---|---|
| Base checkpoint | Pre-trained model with matching tokenizer and configuration | meta-llama/Llama-3.1-8B |
| Instruction dataset | Curated mixture of human-crafted and synthetic examples | 50K conversations, multi-turn |
| Tokenizer | Usually inherited from base model; may need special tokens added | Chat template with markers <|system|>, <|user|>, and <|assistant|> |
| Training configuration | hyper-parameters, precision, parallelism settings | lr=2e-4, BF16, LoRA r=16 |
Outputs
A successful training run produces:
- Model checkpoint that reliably follows instructions across targeted task domains.
- Quality metrics meeting predefined thresholds on evaluation suites (automated + human).
- Safety compliance verified through red-team evaluation and policy adherence tests.
- Reproducibility artifacts like training logs, configuration files, random seeds, container images.
Common Risks and Mitigations
| Risk | Description | Mitigation |
|---|---|---|
| Catastrophic forgetting | Model loses pre-trained capabilities (general knowledge, multilingual fluency) as it overfits the instruction dataset | Use LoRA/PEFT (frozen base weights), include diverse “replay” data, lower learning rate, shorter training |
| Label noise overfitting | Low-quality or inconsistent labels cause the model to learn spurious patterns | Curate high-quality seed data, use rejection sampling on synthetic data, validate inter-annotator agreement |
| Distributional drift | Synthetic teacher outputs shift the learned distribution away from real user queries | Mix synthetic with human-authored data (10-30%), validate on real user queries, use curriculum mixing |
| Silent numerical failures | Quantization/optimizer mismatches cause subtle errors that degrade quality without obvious symptoms | Validate training and inference on same precision, test checkpoints on representative queries, monitor gradient norms |
| Evaluation gaming | Model overfits to specific benchmark formats without genuine capability gain | Use held-out datasets not seen during training, diverse eval suites, human preference evaluation |
Success Criteria
Before investing compute resources in a training run, establish concrete, measurable criteria that define what “success” looks like. This prevents the common pitfall of completing training only to realize the model doesn’t meet requirements—wasting time, energy, and money.
Success criteria fall into four categories: Automated benchmark metrics, safety metrics, training health indicators, and human evaluation results. Each criterion should have a clear threshold that must be met for the run to be considered successful.
Automated Benchmark Metrics
These standardized tests measure specific capabilities. Each benchmark produces a numerical score that can be compared across models. While evaluation benchmarks are covered in detail in Evaluation, here are some examples of possible capability-specific benchmarks:
- MT-Bench: Measures multi-turn conversation quality on a 1–10 scale (higher is better). A score of 7.5+ indicates strong instruction-following.
- GSM8K: Grade-school math word problems; measured as accuracy, i.e. proportion of correctly solved problems.
- HumanEval: Code generation benchmark; “pass\(@1\)” means the model’s first attempt passes all test cases, e.g. pass\(@1 = 0.40\) means 40% of functions generated correctly.
Safety Metrics
These metrics evaluate whether the model appropriately refuses harmful requests and avoids generating toxic content. For example:
- Refusal rate on harmful prompts: What percentage of dangerous/unethical requests does the model correctly refuse? Higher is better.
- Toxicity score: Measures offensive or harmful language in outputs. Lower is better, e.g. 5% of outputs contain some toxicity.
Training Health Indicators
These indicators verify the training process itself ran correctly, independent of final model quality. They help catch issues like numerical instability, overfitting, or data problems early on:
- Final loss: The cross-entropy loss at training end. Lower indicates better fit to training data, but too low suggests overfitting.
- Loss spikes: Sudden jumps in loss indicate numerical instability, exploding gradients, or data issues.
- Gradient norm stability: Gradients should remain bounded; exploding or vanishing gradients signal problems.
Human Evaluation Results
Automated metrics don’t capture everything. Human evaluation provides ground truth for subjective qualities. Key criteria include:
- Preference rate vs. baseline: When humans compare outputs, what percentage prefer your model over an existing baseline?
- Sample size: How many comparisons were made (larger = more statistical confidence).
💡 Tip: Track these metrics throughout training, not just at the end. Early stopping based on validation performance prevents overfitting and saves compute. Tools like Weights & Biases or TensorBoard can alert you when metrics drift outside expected ranges.
Fine-tuning Methods Overview
Instruction tuning methods fall on a spectrum from full parameter updates to highly constrained adaptations. The choice depends on available compute, model size, and how much the target task deviates from the base model’s capabilities.
Full Fine-tuning
Full fine-tuning updates all model weights during training. This approach offers maximum expressiveness—the model can learn entirely new behaviors if needed—but comes with significant costs:
- GPU Memory Requirements: Full fine-tuning demands that a complete copy of the base model weights reside in GPU memory (e.g., ~140GB for a 70B model in BF16). Beyond this, training requires additional GPU memory for optimizer states (Adam stores 2× the model size for momentum and variance), gradients, and intermediate activations during backpropagation. Even when using parameter-efficient methods like LoRA or QLoRA (see next sections), a copy of the full base model must still fit in GPU memory.
- Computational Overhead: Full fine-tuning requires updating all parameters, which increases training time significantly compared to PEFT methods.
- Risk of Overfitting: With all parameters trainable, small datasets can lead to catastrophic forgetting of pre-trained capabilities.
Parameter-Efficient Fine-tuning (PEFT)
PEFT methods adapt a small subset of model parameters while keeping the majority frozen. This dramatically reduces memory requirements and training time while often achieving comparable quality to full fine-tuning (see Mangrulkar et al. (2022)).
Common PEFT approaches include:
| Method | Description | Trainable Params |
|---|---|---|
| LoRA | Low-rank decomposition of weight updates | ~0.1–1% of model |
| Adapters | Small bottleneck layers inserted between transformer blocks | ~1–5% of model |
| IA³ | Learned rescaling vectors for keys, values, and FFN | ~0.01% of model |
| Prefix Tuning | Learnable prefix tokens prepended to each layer | ~0.1% of model |
Among these, LoRA (Low-rank Adaptation) has become the dominant method for instruction tuning due to its simplicity, effectiveness, and zero inference latency when merged (see Hu et al. (2022)).
Understanding LoRA: Low-rank Adaptation
LoRA is based on a key insight: the weight updates during fine-tuning have low intrinsic rank. Instead of updating a weight matrix \(W \in \mathbb{R}^{d \times k}\) directly, LoRA decomposes the update into two smaller matrices:
\[W' = W + \Delta W = W + BA\]
where \(B \in \mathbb{R}^{d \times r}\) and \(A \in \mathbb{R}^{r \times k}\), with rank \(r \ll \min(d, k)\).
Key Hyper-parameters
Rank (
r): The inner dimension of the low-rank matrices. Lower rank means fewer parameters but less expressiveness. Typical values:r=8–16: Good for most instruction tuning tasks.r=32–64: For complex adaptations or larger models.r=4: Minimal adaptation, fastest training.
Alpha (
lora_alpha): A scaling factor applied to the LoRA update. The actual scaling islora_alpha / r, so the update becomes: \[W' = W + \frac{\alpha}{r} \cdot BA\] Common practice is to setlora_alpha = 2 × r(e.g.,r=16, alpha=32). Higher alpha increases the influence of LoRA updates; lower alpha makes training more conservative.Target modules: Which weight matrices to adapt. In standard transformers:
- Attention weights:
q_proj,k_proj,v_proj,o_proj(query, key, value, output projections). - FFN weights:
gate_proj,up_proj,down_proj(feed-forward layers).
For instruction tuning, adapting attention projections (
q_proj,v_proj) is often sufficient. Adding more target modules increases capacity for adapation by allowing more weights to be modified, but also training cost.- Attention weights:
Dropout (
lora_dropout): Regularization applied to LoRA layers. Typical values:0.0–0.1.
Code Example: Configuring LoRA in PEFT
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=16, # Rank of the update matrices
lora_alpha=32, # Scaling factor (alpha/r = 2)
lora_dropout=0.05, # Dropout for regularization
target_modules=[ # Which layers to adapt
"q_proj", "k_proj",
"v_proj", "o_proj"
],
task_type=TaskType.CAUSAL_LM, # Task type for causal language modeling
bias="none", # Whether to train biases: "none", "all", or "lora_only"
)Why LoRA Works Well for Instruction Tuning
- Preserves pre-trained knowledge: The base weights remain frozen, reducing forgetting.
- Modular adapters: Multiple LoRA adapters can be trained for different tasks and swapped at inference time.
- Mergeable: After training, LoRA weights can be merged into the base model with zero inference overhead.
- Memory efficient: Only the small A and B matrices need optimizer states, reducing GPU memory by 3–10× compared to full fine-tuning. This saving is due to two main factors connected to the reduced number of trainable parameters:
- Optimizer states: Adam (and similar optimizers) maintains two additional values (momentum and variance) for each trainable parameter. With LoRA, only the A and B matrices require these states, leading to a significant reduction in memory usage compared to full fine-tuning where all parameters require optimizer states.
- Gradients: During backpropagation, gradients are only computed for the trainable parameters. With LoRA, this means gradients are only calculated for the A and B matrices, further reducing memory requirements.
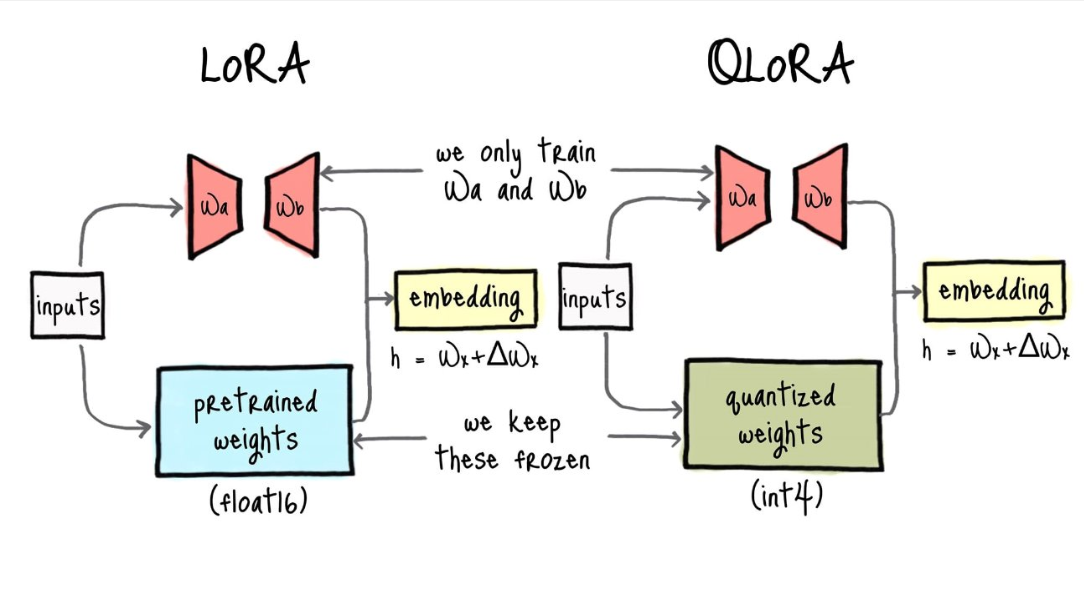
QLoRA: Quantized LoRA
QLoRA extends LoRA by quantizing the frozen base model to 4-bit precision while keeping LoRA adapters in higher precision (BF16/FP16). This enables fine-tuning very large models on modest hardware (see Dettmers et al. (2023)).
Key Components
- 4-bit NormalFloat (NF4): A data type optimized for normally-distributed weights, providing better precision than standard INT4.
- Double quantization: When quantizing the model’s weights, various constants to convert between quantized and original values are stored. These constants include multiplicative scale factors (mapping quantized values, i.e. 0-15 in 4-bit, to their original range), zero points (reference value to anchor the quantized values), and min/max bounds (representing the original range of the weights). Double quantization refers to the practice of quantizing such constants themselves, saving an additional ~0.4 bits per parameter.
- Paged optimizers: An optional optimization that moves optimizer states (momentum and variance buffers) from GPU to CPU memory when GPU memory is exhausted. This is automatic when enabled via
bnb_4bit_use_paged_adamw8bit=True, but requires NVIDIA GPUs with unified memory support. Trading increased CPU-GPU communication for reduced GPU memory usage, this is a memory-handling optimization rather than a required component: useful when facing OOM errors, but introduces some training latency overhead.
When to Choose QLoRA
| Scenario | Recommendation |
|---|---|
| 7B model on 24GB GPU | Use LoRA with BF16 |
| 13B model on 24GB GPU | Use QLoRA |
| 70B model on 48GB GPU | Use QLoRA with gradient checkpointing |
| Maximum quality required | Use LoRA with BF16 if memory allows |
Code Example: QLoRA configuration
from transformers import BitsAndBytesConfig
import torch
# 4-bit quantization configuration
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enable 4-bit loading
bnb_4bit_quant_type="nf4", # Use NormalFloat4 quantization
bnb_4bit_use_double_quant=True, # Double quantization for memory savings
bnb_4bit_compute_dtype=torch.bfloat16 # Compute in BF16 for stability
)
# Load model with quantization
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B",
quantization_config=bnb_config,
device_map="auto"
)⚠️ Note: QLoRA introduces slight overhead during training (de-quantization in the forward pass) and may show marginally different convergence compared to BF16 LoRA. Validate on a held-out set before committing to a full training run.
LoRA and QLoRA: Trade-offs vs Full Fine-tuning
The choice between full fine-tuning, LoRA, and QLoRA is fundamentally about trading memory and compute efficiency against expressiveness and quality:
| Aspect | Full Fine-tuning | LoRA | QLoRA |
|---|---|---|---|
| GPU Memory | ~2-3× model size | ~5-10% overhead | ~10-15% overhead |
| Training Speed | Baseline (slowest) | 2-3× faster | ~2× faster (dequant overhead) |
| Expressiveness | Maximum; can learn entirely new behaviors | Good for most tasks; limited by rank | Similar to LoRA; quantization introduces approximation error |
| Quality on hard domain shifts | Best; can fundamentally rewire the model | May plateau on very different tasks | May plateau earlier due to quantization |
| Inference Latency | No added cost after merge | Zero additional latency when merged | Zero additional latency when merged |
| Best use case | When compute is abundant and quality is critical | Standard instruction tuning with moderate hardware | Large models on limited hardware (e.g., 70B on 24GB GPU) |
In practice: choose full fine-tuning when quality is paramount and hardware permits; use LoRA for balanced efficiency and quality; use QLoRA when scaling to very large models on constrained hardware.
Preventing Catastrophic Forgetting
Catastrophic forgetting is one of the most common failure modes in instruction tuning: the model learns the new task well but loses capabilities it had after pre-training: general knowledge, multilingual fluency, coding ability, or common-sense reasoning that wasn’t covered in the fine-tuning dataset.
Neural networks store knowledge distributed across their weights. When gradient updates are applied repeatedly for a narrow set of examples, those weights shift to minimize loss on the new data, overwriting the representations built during pre-training. The model can become highly capable on the fine-tuning distribution while regressing significantly on anything outside it.
Typical symptoms:
- Strong benchmark performance on the target task, but noticeable regression on held-out general benchmarks MMLU (Hendrycks et al. (2020)), and HellaSwag (Zellers et al. (2019)).
- The model refuses requests it previously handled, or generates repetitive or incoherent outputs on out-of-distribution prompts.
- Multilingual capability degrades if the fine-tuning dataset is monolingual.
Using PEFT to Freeze Pre-Trained Knowledge
A possible structural defense against catastrophic forgetting is PEFT. By keeping base weights frozen and training only small adapter matrices, the pre-trained knowledge is physically protected from gradient updates. The adapter learns the delta required for the new task without touching the underlying representations.
Loss Masking and Label Construction
A critical but often overlooked aspect of instruction tuning is how the training loss is computed. Unlike pre-training where the model learns to predict every token, instruction tuning typically focuses the loss on specific parts of the sequence—usually the model’s responses, not the user’s prompts.
The Standard Cross-entropy Loss
During training, the model predicts the next token at each position, and the loss measures how well these predictions match the ground truth:
\[\mathcal{L}_{\text{SFT}}(\theta) = -\sum_{t=1}^{T} \log p_\theta(y_t \mid y_{<t})\]
where \(y_t\) is the target token at position \(t\) and the model is conditioned on all previous tokens. In practice, one may want to mask out some tokens from contributing to the loss, as explained in the next section. In such a case, each token is assigned a weight \(w_t\) (0 for masked tokens, 1 for unmasked), and the loss becomes: \[\mathcal{L}_{\text{SFT}}(\theta) = -\sum_{t=1}^{T} w_t \log p_\theta(y_t \mid y_{<t})\]
Why Mask the Prompt?
Consider a typical instruction-tuning example:
<|user|>What is the capital of France?<|assistant|>The capital of France is Paris.If we compute loss on the entire sequence, the model is “rewarded” for predicting the user’s question—but this isn’t useful for instruction-following. We want the model to learn how to respond, not how to generate user queries.
Prompt masking (also called “completion-only loss”) sets the loss to zero for prompt tokens by replacing their labels with a special ignore index (typically -100 in PyTorch). The model still sees these tokens during the forward pass (they provide context), but receives no gradient signal from them.
Masking Strategies
| Strategy | What is masked | When to use |
|---|---|---|
| Completion-only | All prompt tokens | Standard SFT—train only on assistant responses |
| Assistant-only | System + user tokens | Multi-turn conversations—train on all assistant turns. When there is only one turn, this case reduces to the completion-only case. For this reason, the two will be used somewhat interchangeably below. |
| Full sequence | Nothing masked | Pre-training style, or when both sides matter |
How Masking Works in Practice
The masking is implemented via the labels tensor. Consider this tokenized example:
input_ids: [USR, What, is, the, capital, ?, ASST, The, capital, is, Paris, .]
labels: [-100, -100, -100, -100, -100, -100, -100, The, capital, is, Paris, .]Tokens with label -100 are ignored in the cross-entropy loss computation. The model learns from predicting “The”, “capital”, “is”, “Paris”, and “.” but not from predicting the question tokens.
For multi-turn conversations, this is typically handled with a completion mask:
# Example: Multi-turn with assistant-only loss
messages = [
{"role": "user", "content": "What is 2+2?"},
{"role": "assistant", "content": "2+2 equals 4."},
{"role": "user", "content": "And 3+3?"},
{"role": "assistant", "content": "3+3 equals 6."}
]
# After tokenization with masking:
# Loss computed only on: "2+2 equals 4." and "3+3 equals 6."Implementing Loss Masking
Loss masking can be easily implemented by hand, by pre-processing every batch irrelevant token labels equal to -100. However, there is also the option in most modern training libraries handle this automatically. In TRL’s SFTTrainer, we would use configuration:
from trl import SFTConfig
# Train only on completion (assistant) tokens
config = SFTConfig(
output_dir="./output",
completion_only_loss=True, # For prompt-completion datasets
# OR
assistant_only_loss=True, # For conversational datasets
)For manual implementation with the DataCollatorForLanguageModeling:
from trl.trainer.sft_trainer import DataCollatorForLanguageModeling
collator = DataCollatorForLanguageModeling(
pad_token_id=tokenizer.pad_token_id,
completion_only_loss=True, # Mask prompt tokens
)
# The collator will set labels to -100 for tokens where completion_mask == 0💡 Best practice: Always use completion-only or assistant-only loss for instruction tuning. Training on user prompts can bias the model toward generating question-like text and reduces the effective training signal for response generation.
Tooling and Libraries
A well-integrated toolchain accelerates iteration and reduces errors. The following libraries form the core stack for instruction tuning:
| Library | Purpose | When to Use |
|---|---|---|
| Transformers | Model loading, tokenization, base Trainer | Always—foundation for model I/O |
| PEFT | LoRA, QLoRA, adapters | When using parameter-efficient methods |
| TRL | SFTTrainer, DPO, PPO | For instruction tuning and RLHF workflows |
| Accelerate | Distributed training, mixed precision | Multi-GPU or multi-node training |
| DeepSpeed | ZeRO optimization, offloading | Training very large models |
| bitsandbytes | 8-bit/4-bit quantization | QLoRA training |
| vLLM | High-throughput inference | Serving and evaluation |
Integration Example: How Libraries Work Together
The libraries in the table above represent one popular and well-documented approach to instruction tuning, but they are not the only option. Alternative frameworks include Axolotl (a configuration-driven wrapper that simplifies complex training setups), LLaMA-Factory (which provides a unified interface for various fine-tuning methods), Unsloth (optimized for speed on consumer hardware), and direct use of PyTorch or TorchTitan with custom training loops for maximum flexibility. Some teams prefer JAX and Flax ecosystems, particularly for TPU training, while others use NeMo from NVIDIA for production-scale workflows.
The HuggingFace stack (TRL + PEFT + Accelerate) is presented here because of its extensive documentation, active community, and seamless integration with the HuggingFace Hub. However, practitioners should choose the tooling that best fits their infrastructure, team expertise, and specific requirements. The libraries described below are designed to integrate seamlessly, each handling a specific aspect of the training pipeline. Understanding which library handles which responsibility helps you debug issues and customize behavior when needed.
TRL as the orchestration layer. TRL’s SFTTrainer serves as the entry point for most instruction tuning workflows. When you instantiate an SFTTrainer, it coordinates all the other libraries behind the scenes. It loads the model and tokenizer using Transformers, applies chat templates to your dataset, configures loss masking so that training focuses only on assistant responses, and manages the training loop including logging and checkpointing. You interact primarily with TRL’s API, while it delegates to specialized libraries for specific tasks.
Transformers for model infrastructure. Although you may not import Transformers directly when using TRL, it provides the foundational infrastructure. Transformers handles loading pre-trained weights from the HuggingFace Hub (or local paths), provides the model architecture definition, manages the tokenizer with its chat template, and executes the forward and backward passes. When you pass a model identifier like "meta-llama/Llama-3.1-8B" to SFTTrainer, Transformers’ AutoModelForCausalLM.from_pretrained() is called internally to load the model.
PEFT for parameter-efficient adaptation. When you provide a peft_config to SFTTrainer, PEFT takes over adapter injection. It inserts LoRA (or other adapter) layers into the specified target modules, freezes the original model weights so they don’t receive gradient updates, and ensures that only the adapter parameters are trained. After training, PEFT enables saving just the adapter weights (typically 50–200 MB instead of the full model) and supports merging adapters back into the base model for deployment.
Accelerate for distributed training and precision. Accelerate operates mostly invisibly but handles critical infrastructure concerns. When you set bf16=True in your training configuration, Accelerate manages mixed-precision training—keeping a master copy of weights in full precision while using BF16 for forward and backward passes. When you launch your script with accelerate launch, it handles distributing the model and data across multiple GPUs, synchronizing gradients between processes, and managing device placement. The same training script works on one GPU or many without code changes.
DeepSpeed and bitsandbytes for advanced optimization. For very large models or memory-constrained setups, DeepSpeed provides ZeRO (Rajbhandari et al. (2020)) optimizer states sharding and CPU/NVMe offloading (see Rajbhandari et al. (2021)), while bitsandbytes enables 4-bit and 8-bit quantization for QLoRA training. These integrate through Accelerate’s configuration system—you specify them in a configuration file rather than changing your training code.
A Complete Example
The following script demonstrates all these libraries working together. The code itself is straightforward because the complexity is handled by the library integration:
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig
from datasets import load_dataset
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
bias="none",
)
training_config = SFTConfig(
output_dir="./sft-output",
bf16=True,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.05,
num_train_epochs=1,
logging_steps=10,
save_strategy="steps",
save_steps=500,
max_seq_length=2048,
packing=True,
)
dataset = load_dataset("trl-lib/Capybara", split="train")
trainer = SFTTrainer(
model="meta-llama/Llama-3.1-8B",
args=training_config,
train_dataset=dataset,
peft_config=lora_config,
)
trainer.train()
trainer.save_model()Launching Training at Different Scales
The same script adapts to different hardware configurations through the launch command:
For single-GPU training, simply run the script directly. Accelerate still handles mixed precision internally:
python train.pyFor multi-GPU training on a single machine, use accelerate launch. This distributes the workload across all specified GPUs using data parallelism, where each GPU processes different batches and gradients are synchronized:
accelerate launch --num_processes 4 --mixed_precision bf16 train.pyFor memory-constrained scenarios with very large models, integrate DeepSpeed via an Accelerate configuration file. DeepSpeed’s ZeRO stages shard optimizer states (ZeRO-1), gradients (ZeRO-2), or parameters (ZeRO-3) across GPUs:
accelerate launch --config_file deepspeed_config.yaml train.pyFor multi-node training on HPC clusters, launch the same command on each node with appropriate rank and network configuration:
accelerate launch \
--num_processes 8 \
--num_machines 2 \
--machine_rank 0 \
--main_process_ip <MAIN_NODE_IP> \
--main_process_port 29500 \
train.pyDebugging Common Issues
When something goes wrong, knowing which library is responsible helps you search for solutions in the right documentation:
| Issue | Likely Culprit | How to Debug |
|---|---|---|
| Model fails to load | Transformers | Check model ID, authentication (huggingface-cli login). Alternatively, check that model doesn’t exceed the memory available |
| CUDA out of memory | Accelerate or PEFT | Reduce batch size, enable gradient checkpointing, use QLoRA |
| Loss is NaN | Accelerate (precision) | Try FP32, check for inf or NaN in data, reduce learning rate, clip gradient norm |
| Adapter not saving | PEFT | Ensure trainer.save_model() called, check disk space |
| Training hangs at start | Accelerate (distributed) | Check network, GPU visibility (CUDA_VISIBLE_DEVICES). Check NCCL debug logs if available |
| Poor final quality | TRL/PEFT configuration | Check dataset format, loss masking, LoRA rank |
| Template mismatch | TRL | Verify tokenizer has correct chat_template |
Training Configuration
Choosing the right hyper-parameters is one of the most consequential decisions in a fine-tuning run. Unlike pre-training, where defaults from large-scale experiments are well-established, instruction tuning operates on smaller datasets with tighter compute budgets—meaning poor choices compound quickly into wasted runs or degraded model quality. This section walks through each key hyper-parameter, explains the reasoning behind recommended values, and highlights the interactions between them.
Learning Rate
The learning rate controls how aggressively the optimizer updates weights at each step. Getting it right is a balancing act: too high and the optimizer overshoots good minima or destroys the pre-trained representations the model spent thousands of GPU-hours learning; too low and training converges slowly, wastes compute, or gets stuck in suboptimal regions.
The appropriate range depends heavily on what is being trained. In full fine-tuning, every weight in the model is updated, so a high learning rate risks catastrophic forgetting—the model rapidly overwrites the general knowledge encoded during pre-training. Rates in the 1e-5 to 5e-5 range keep updates conservative enough to preserve pre-trained representations while still learning new instruction-following behavior. In LoRA and other PEFT methods, the base weights are frozen and only the small adapter matrices receive gradient updates. Because these adapters start from a near-zero initialization and have far fewer parameters, they can tolerate—and often require—higher learning rates (1e-4 to 3e-4) to learn meaningful adaptations within a reasonable number of steps.
A practical starting point: use 2e-4 for LoRA on 7–13B models. If you observe loss spikes during training, reduce the rate by half. If the loss plateaus early and the model underperforms on evaluation, try increasing it. For full fine-tuning of smaller models (1–3B), 2e-5 is a reasonable default. Note that LoRA rank also influences this choice: higher ranks introduce more trainable parameters, which may require slightly more conservative learning rates; conversely, very low ranks (e.g., r=4) can tolerate higher rates since they have fewer parameters to destabilize training.
| Method | Recommended Range | Starting Point |
|---|---|---|
| Full fine-tuning | 1e-5 – 5e-5 |
2e-5 |
| LoRA / PEFT | 1e-4 – 3e-4 |
2e-4 |
| QLoRA | 1e-4 – 2e-4 |
1e-4 |
💡 Tip: When in doubt, run two short experiments (500–1,000 steps) at different learning rates and compare the loss curves. This “learning rate range test” costs little compute and prevents committing hours of training to a suboptimal setting.
Batch Size and Gradient Accumulation
The effective batch size—the total number of examples the optimizer sees before each weight update—is one of the most impactful training hyper-parameters. It directly controls the signal-to-noise ratio of gradient estimates: larger batches average over more examples, producing smoother and more accurate gradient directions, while smaller batches introduce more noise, which can act as a form of regularization.
In practice, the per-device batch size is constrained by GPU memory (a 7B model in BF16 with LoRA leaves room for only a handful of sequences per GPU), so gradient accumulation is the standard mechanism for increasing the effective batch without requiring more hardware. The optimizer accumulates gradients over multiple forward-backward passes and applies a single weight update after the specified number of steps:
\[\text{Effective Batch Size} = \text{per\_device\_batch\_size} \times \text{gradient\_accumulation\_steps} \times \text{num\_GPUs}\]
The choice of effective batch size interacts with both the learning rate and the number of training epochs. A larger batch means fewer optimizer steps per epoch, so the model sees the same data but makes fewer (and individually more stable) updates. If you double the effective batch size, consider also increasing the learning rate proportionally (the “linear scaling rule”—see Distributed Training Considerations below) to maintain the same effective step size in weight space.
There is no universally optimal batch size for instruction tuning, but the following guidelines hold across most setups:
- Small datasets (< 10K examples): use smaller effective batches (16–32) to maximize the number of optimizer steps per epoch. With too few updates, the model doesn’t have enough optimization steps to converge.
- Larger datasets (50K+): effective batches of 64–256 work well, reducing training time while maintaining quality.
- A common starting point:
per_device_batch_size=4withgradient_accumulation_steps=8gives an effective batch of 32 on a single GPU—large enough for stable gradients, small enough for sufficient steps per epoch on most datasets.
from trl import SFTConfig
config = SFTConfig(
# ...
per_device_train_batch_size=4,
gradient_accumulation_steps=8, # Effective batch = 4 × 8 = 32 per GPU
per_device_eval_batch_size=8, # Can be larger since no gradients stored
)Warmup and Schedulers
Learning rate schedulers control how the rate evolves across training. The most important phase is warmup: the first few hundred steps where the learning rate ramps from near-zero to its target value.
Why is warmup necessary? At the start of training, the optimizer’s adaptive state (Adam’s momentum and variance estimates) is initialized to zero—it has no history of gradient magnitudes. Without history, Adam effectively applies raw gradient updates without proper scaling, which can cause the first few weight updates to be disproportionately large and destabilizing. The warmup phase gives the optimizer time to accumulate meaningful statistics before the learning rate reaches its full value, preventing early training instability that can manifest as loss spikes or divergence.
After warmup, the scheduler determines how the rate decays toward the end of training:
- Cosine decay (recommended default): after warmup, the rate follows a half-cosine curve from the peak down to near zero. This produces gentle, smooth convergence in the final phase of training and is empirically the best-performing schedule for most fine-tuning scenarios.
- Linear decay: a simpler alternative that decays the rate linearly. Tends to produce sharper late-stage loss drops and can work well, but generally slightly underperforms cosine.
- Constant schedule: maintains the peak rate throughout training (no decay). Useful for very short runs or hyper-parameter sweeps, but risks overfitting in longer training since the optimizer never slows down.
- Cosine with restarts: periodically resets the cosine cycle, which can help escape local minima. Occasionally useful for multi-phase training but adds complexity.
The warmup duration is typically expressed as either a fraction of total steps (warmup_ratio) or a fixed step count (warmup_steps). A ratio of 3–5% of total training steps works well for most instruction tuning runs. For very short runs (under 1,000 steps), a fixed warmup of 50–100 steps is more predictable than a ratio.
from trl import SFTConfig
config = SFTConfig(
# ...
learning_rate=2e-4,
lr_scheduler_type="cosine", # "linear", "cosine", "constant", "cosine_with_restarts"
warmup_ratio=0.03, # 3% of total steps used for warmup
# OR use warmup_steps=100 for a fixed count (takes precedence over ratio if both set)
)Mixed Precision
Training in full FP32 precision is almost never necessary for instruction tuning. Because the model weights are already pre-trained (and often distributed in BF16/FP16 format), the fine-tuning phase inherits the same numerical stability characteristics and benefits from half-precision computation: roughly half the memory footprint and significantly faster matrix operations on modern GPUs.
The key distinction between the two 16-bit formats is dynamic range:
BF16 (Brain Float 16) uses an 8-bit exponent (same as FP32) and a 7-bit mantissa. The wide exponent range means it can represent the same magnitudes as FP32—from very small gradient values to very large activations—without risk of overflow or underflow. This makes BF16 numerically robust and eliminates the need for loss scaling. Available on NVIDIA Ampere (A100) and later architectures (H100, L40S), as well as AMD MI250/MI300.
FP16 (IEEE Half Precision) uses a 5-bit exponent and 10-bit mantissa. The narrower exponent range means extremely small gradient values (common in early layers of deep networks) can underflow to zero, and large activation values can overflow to infinity. To work around this, FP16 training requires dynamic loss scaling: the loss is multiplied by a large factor before back-propagation (to push small gradients into the representable range), and gradients are divided by the same factor before the optimizer step. Most frameworks handle this automatically, but it adds complexity and can occasionally cause training instability if the scale factor oscillates.
FP32 should only be used for debugging numerical issues or when training very small models where the memory savings of half precision are irrelevant.
| Precision | Exponent / Mantissa | Dynamic Range | Loss Scaling Required | Hardware |
|---|---|---|---|---|
| BF16 | 8 / 7 bits | Same as FP32 | No | Ampere+ (A100, H100), MI250+ |
| FP16 | 5 / 10 bits | Narrower | Yes (automatic) | All modern GPUs (V100, T4, A100+) |
| FP32 | 8 / 23 bits | Full | No | All GPUs |
Recommendation: use BF16 whenever your hardware supports it. It is strictly simpler and more stable than FP16 for training, with no quality trade-off for instruction tuning workloads. Fall back to FP16 only on older hardware (V100, T4). For a deeper dive into numerical formats and their implications, see Precision and Data Types in Guide 2.
config = SFTConfig(
# ...
bf16=True, # Use bfloat16 on Ampere+ GPUs
# fp16=True, # Use this instead on Volta/Turing GPUs
)Gradient Clipping
Gradient clipping limits the norm of the gradient vector before the optimizer step, preventing a single noisy or corrupted batch from causing a catastrophically large weight update. Without clipping, an outlier batch—one containing an unusually long sequence, a data formatting error, or a numerical edge case—can produce a gradient with an enormous norm. A single unclipped update of this magnitude can undo many steps of careful optimization, manifesting as a sudden loss spike that the model may take hundreds of steps to recover from (or never recover from at all).
The standard formulation is global norm clipping: if the L2 norm of the concatenated gradient vector exceeds a threshold, all gradients are uniformly rescaled so the total norm equals the threshold:
\[g \leftarrow g \cdot \min\left(1,\ \frac{\text{max\_norm}}{\|g\|}\right)\]
This preserves the direction of the gradient (the relative magnitudes across parameters stay the same) while bounding its magnitude.
- Standard value:
max_grad_norm=1.0is the overwhelmingly common choice and works well for the vast majority of instruction tuning runs. Most frameworks (including HuggingFace Transformers) default to this value. - Lower values (
0.3–0.5) add extra stability when training with very long sequences (8K+ tokens), aggressive learning rates, or unstable data mixtures. - Diagnostic use: monitor the
grad_normmetric in your training logs (Weights & Biases, TensorBoard, or log output). If the gradient norm is consistently clipped (at or nearmax_grad_normevery step), this signals that the learning rate is too aggressive for the data—reduce the learning rate rather than lowering the clip threshold.
config = SFTConfig(
# ...
max_grad_norm=1.0,
)Checkpointing
Checkpointing serves two distinct purposes: fault recovery (resuming after preemption or hardware failure) and model selection (keeping the best checkpoint rather than the final one). On HPC clusters where SLURM job preemption is common, checkpointing strategy directly determines how much compute is wasted per interruption.
Save frequency should be calibrated to your cluster’s preemption patterns and the total training duration. For short runs (under 2 hours), saving every 200–500 steps is appropriate. For longer runs on shared HPC systems where jobs may be preempted unpredictably, save every 1,000–2,000 steps. The goal is to ensure that a preemption never costs more than 15–30 minutes of re-computation. PEFT checkpoints are particularly inexpensive to save (50–200 MB for LoRA adapters vs. tens of GB for full model checkpoints), so saving more frequently has negligible overhead.
Model selection via validation is critical because the final checkpoint is not always the best one. Training loss continues to decrease as the model memorizes training examples, but generalization (as measured by validation loss or downstream benchmarks) typically peaks and then degrades. To capture the best generalizing checkpoint:
config = SFTConfig(
# ...
save_strategy="steps",
save_steps=500,
save_total_limit=3, # Keep only the 3 best checkpoints to save storage
load_best_model_at_end=True, # After training, load the best checkpoint (not the last)
eval_strategy="steps",
eval_steps=500, # Must match save_steps for load_best_model_at_end
metric_for_best_model="eval_loss", # Selection criterion
)💡 Tip: On SLURM clusters with preemption, always set
save_stepsto a value shorter than your typical job time slice. A checkpoint saved 10 minutes before preemption beats restarting from scratch. Also ensure your training script supportsresume_from_checkpointto avoid restarting from step 0 after every interruption.
Distributed Training Considerations
When scaling instruction tuning from a single GPU to multiple GPUs or multiple nodes, several training dynamics change in ways that require explicit configuration adjustments. Failing to account for these can lead to silently degraded model quality—the training appears to complete normally, but the resulting model underperforms compared to a properly configured single-GPU run.
Learning rate scaling. The most important adjustment when increasing the number of GPUs is the learning rate. In data-parallel training (the default mode in Accelerate and DeepSpeed), each GPU processes a different micro-batch, and gradients are averaged across all GPUs via an AllReduce operation before the optimizer step. This means the effective batch size increases linearly with the number of GPUs. A gradient estimated from 4× more samples is 4× less noisy—effectively a 4× larger step in the “true” gradient direction. To maintain the same training dynamics as the single-GPU baseline, the learning rate should be scaled accordingly.
The standard approach is the linear scaling rule: multiply the base learning rate by the number of GPUs (or more precisely, by the ratio of the new effective batch size to the original):
\[\text{lr}_{\text{scaled}} = \text{lr}_{\text{base}} \times \frac{\text{effective\_batch\_new}}{\text{effective\_batch\_base}}\]
For example, going from 1 GPU to 4 GPUs (with the same per-device batch size and accumulation steps) means the effective batch quadruples, so the learning rate should also be multiplied by 4:
| GPUs | Effective Batch | LR (linear scaling) |
|---|---|---|
| 1 | 32 | 2e-4 (base) |
| 4 | 128 | 8e-4 |
| 8 | 256 | 1.6e-3 |
Linear scaling works well for moderate scaling factors (up to ~8–16×), but it breaks down at very large effective batch sizes (generally beyond 2K–8K for instruction tuning). At that point, gradient estimates become so accurate that the optimizer takes large, confident steps—but the loss landscape is complex enough that such large steps overshoot local minima. A more conservative square-root scaling rule (\(\text{lr} \times \sqrt{N}\)) is preferable for large GPU counts.
⚠️ Important: Most training frameworks—including HuggingFace’s Trainer, TRL, and Accelerate—do not automatically adjust the learning rate when you change the number of GPUs. You must do this manually in your training configuration. Forgetting to scale the learning rate is one of the most common causes of “it trained fine on 1 GPU but quality degraded on 8”.
Warmup adjustment. When the learning rate is scaled up for distributed training, the warmup phase becomes even more critical. A higher peak learning rate means the optimizer is more sensitive to the cold-start problem described above. Increase the warmup proportionally—if your single-GPU run uses 100 warmup steps, use 200–400 when scaling to 4–8 GPUs.
Gradient accumulation interaction. Gradient accumulation and multi-GPU training are mathematically equivalent ways to increase the effective batch size—they produce the same averaged gradients. This means they are interchangeable: going from 1 GPU with gradient_accumulation_steps=8 to 4 GPUs with gradient_accumulation_steps=2 produces the same effective batch of 32 (assuming per_device_batch_size=4 in both cases) and requires no learning rate adjustment. Be careful not to accidentally multiply both: going to 4 GPUs while keeping gradient_accumulation_steps=8 would quadruple the effective batch and require a corresponding LR increase.
Communication overhead for PEFT methods. A common misconception is that LoRA fine-tuning doesn’t benefit from multi-GPU training because the trainable parameter count is small. While the gradient AllReduce is indeed cheaper (only adapter parameters need synchronization), the primary bottleneck is often the forward pass through the (frozen) full model, which benefits from data parallelism just as much as full fine-tuning. However, for very small adapter sizes on fast interconnects, the communication-to-computation ratio can become unfavorable—profiling with torch.profiler or Accelerate’s built-in logging is recommended before committing to large-scale distributed LoRA runs.
Data loading and shuffling. In distributed training, each GPU must see different data in every step. Frameworks like Accelerate and PyTorch’s DistributedSampler handle this automatically by assigning different shard offsets to each process. However, two pitfalls are common:
- Forgetting to set the epoch on the sampler: if the sampler’s random seed isn’t updated between epochs, GPUs may see the same data ordering in every epoch, reducing effective diversity.
- Uneven dataset sizes: if the dataset size is not evenly divisible by the number of GPUs, the last micro-batch may be incomplete. Most frameworks pad or drop the remainder, but this can cause divergent gradient norms between GPUs if not handled consistently.
Synchronization and determinism. All GPUs must begin each training step with identical model weights. The AllReduce operation ensures gradients are identical before the optimizer step, but numerical differences across GPUs (different operation orderings, non-deterministic cuDNN kernels) can introduce tiny floating-point discrepancies that accumulate over thousands of steps. For reproducible distributed training, set deterministic flags and verify that loss values match across ranks in the first few steps.
Multi-node networking. When training spans multiple nodes, network bandwidth and latency become critical. The AllReduce gradient synchronization happens at every optimizer step, and its cost is proportional to the number of parameters being synchronized (all parameters for full fine-tuning, only adapter parameters for LoRA). On HPC clusters with InfiniBand (200–400 Gb/s), multi-node overhead is typically small (5–15%). On commodity Ethernet (10–25 Gb/s), it can become the training bottleneck. For multi-node instruction tuning on bandwidth-constrained networks, consider:
- Increasing gradient accumulation steps to reduce the frequency of AllReduce operations.
- Using ZeRO-1 (Rajbhandari et al. (2020)) (optimizer-only sharding) which has the lowest communication overhead among ZeRO stages.
- For full fine-tuning of large models, ZeRO-3 (Rajbhandari et al. (2021)) or FSDP may be necessary for memory reasons, but their communication overhead is higher—ensure your interconnect can sustain it.
# Example: Properly configured distributed LoRA fine-tuning on 4 GPUs
# Base config was: lr=2e-4, per_device_batch=4, accumulation=8, effective_batch=32
# With 4 GPUs: reduce accumulation to keep same effective batch, OR scale LR
# Option A: Keep effective batch the same (recommended for small datasets)
config = SFTConfig(
learning_rate=2e-4, # Same LR, same effective batch
per_device_train_batch_size=4,
gradient_accumulation_steps=2, # Reduced from 8 → 2 (4 GPUs compensate)
warmup_ratio=0.03,
)
# Option B: Increase effective batch and scale LR (better for large datasets)
config = SFTConfig(
learning_rate=8e-4, # 4× LR for 4× effective batch
per_device_train_batch_size=4,
gradient_accumulation_steps=8, # Same accumulation → 4× effective batch
warmup_ratio=0.05, # Slightly longer warmup for higher LR
)Mixing General Data with Instruction Data
When full fine-tuning is required, or when forgetting persists despite PEFT, data replay (also called experience replay or data mixing) is the standard mitigation. A small fraction of general pre-training style data is mixed into the instruction fine-tuning batches. Note that masking strategies differ across data types: instruction examples apply the completion-only or assistant-only masking strategies described in the Loss Masking section above, while general pre-training data is trained on all tokens (no masking besides padding).
- Typical mixing ratio: 5–20% general data alongside instruction examples. Higher ratios improve retention at the cost of slowing task-specific learning.
- General data sources: open-web text (Common Crawl subsets), Wikipedia, code corpora, or a random sample from the original pre-training mixture.
- Curriculum strategies: some practitioners ramp up the instruction proportion over training (start at 50/50, end at 90/10) to stabilize early adaptation before focusing on the target task.
Regularization Techniques
Several optimization-level techniques directly reduce the rate at which new gradients overwrite old weights:
- Lower learning rate: the simplest and most effective knob. A learning rate of
1e-5instead of1e-4slows the rate of weight change and provides more time for the optimizer to find a good compromise between old and new tasks. - Weight decay (L2 regularization): applying a small penalty (
weight_decay=0.01–0.1) on weight magnitudes pulls weights toward their initialization, implicitly anchoring them near the pre-trained values. - Fewer training epochs: over-training on a small instruction dataset is a primary driver of forgetting. Evaluating on a diverse held-out set and stopping early when general metrics start to degrade is often more effective than any regularization technique on its own.
- Elastic Weight Consolidation (EWC): a research technique that adds a regularization term penalizing changes to weights deemed important for previous tasks (estimated via the Fisher information matrix). Less commonly used in production but available in some continual learning libraries.
Validating on Diverse Held-out Sets
Forgetting is invisible unless you measure it. The critical practice is maintaining a multi-domain validation suite that is evaluated at regular intervals throughout training—not just at the end:
- Include at least one general-knowledge benchmark (e.g., MMLU or a held-out slice of your pre-training eval set).
- Include your target-task benchmark(s).
- Track both throughout training: if general benchmarks degrade while target-task metrics improve, you are observing forgetting in real time and can intervene (reduce LR, increase replay ratio, or stop early).
- For multilingual models, include a multilingual evaluation set even if the instruction data is monolingual.
⚠️ Warning: Using only the fine-tuning task’s validation loss as the stopping criterion will always select the most over-fitted checkpoint. Diverse held-out evaluation is the correct stopping signal.
Reproducibility and Audit
Reproducible training is essential for scientific rigor, debugging, and regulatory compliance (especially relevant for EU AI Act considerations). Instruction tuning involves many moving parts—model versions, training scripts, hyper-parameters, data preprocessing steps, random seeds, and hardware configurations—all of which can influence the final model quality. Without systematic recording of these factors, it becomes impossible to reproduce results, compare runs, or understand why a particular training run succeeded or failed.
Reproducibility Checklist
| Category | What to Record | How |
|---|---|---|
| Code | Git commit hash, branch, diffs | git rev-parse HEAD |
| Environment | Python packages, CUDA version | pip freeze, container image tag |
| Data | Dataset version, preprocessing hash | HuggingFace dataset revision, checksum |
| Configuration | All hyper-parameters | Save configuration YAML/JSON with checkpoint |
| Seeds | Random seeds for all libraries | Set explicitly and log |
Setting Seeds for Reproducibility
import random
import numpy as np
import torch
def set_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# For full determinism (may impact performance)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)⚠️ Note: Full determinism on GPU can reduce performance. For production training, prioritize logging all seeds and configurations; accept minor non-determinism in exchange for speed.
4.1.3 Evaluation
Evaluating instruction-tuned models is both critical and challenging. Unlike traditional supervised learning tasks where a single metric (accuracy, F1) suffices, instruction-tuned models operate across open-ended domains where “correctness” is multidimensional and often subjective. A response can be factually accurate but unhelpful, or helpful but verbose, or concise but unsafe. This section provides a structured approach to evaluation that balances automated efficiency with human judgment.
Why Evaluation is Hard for Instruction-Tuned Models
Traditional NLP evaluation relies on reference-based metrics: compare model output to ground truth and compute overlap (Papineni et al. (2002) BLEU, Lin (2004) ROUGE, exact match). For instruction-following, this breaks down for several reasons:
No single correct answer: For most prompts, many valid responses exist. “What’s a good recipe for dinner?” has thousands of acceptable answers.
Quality is multidimensional: A response must simultaneously be helpful, accurate, safe, well-formatted, appropriately detailed, and aligned with user intent.
Distribution shift: Models trained on curated instruction data encounter real-world queries that differ significantly in style, complexity, and domain.
Benchmark saturation: As models improve, older benchmarks become less discriminative. A model scoring 95% on a benchmark tells you little about comparative quality.
Goodhart’s Law: When benchmarks become targets, models (and training pipelines) optimize for benchmark-specific patterns rather than genuine capability. A model might excel at GSM8K-style math problems but fail on equivalent problems with different phrasing.
For these reasons, robust evaluation requires a layered strategy combining automated benchmarks, LLM-based judges, and targeted human evaluation.
Evaluation Dimensions
Before selecting benchmarks, clarify what properties you’re evaluating:
| Dimension | Description | Example Failure |
|---|---|---|
| Instruction following | Does the model do what was asked? | Asked for a haiku, writes a paragraph |
| Factual accuracy | Are claims correct and verifiable? | States incorrect historical dates |
| Reasoning quality | Are logical steps sound? | Makes arithmetic errors, invalid deductions |
| Helpfulness | Is the response useful for the user’s goal? | Technically correct but misses the point |
| Safety | Does it avoid harmful content? | Provides dangerous advice when asked |
| Calibration | Does confidence match accuracy? | Expresses high certainty on wrong answers |
| Formatting | Does output match requested structure? | Returns prose when JSON requested |
| Verbosity | Is length appropriate? | One-sentence answer to complex question |
No single benchmark captures all dimensions. Design your evaluation suite to cover the dimensions most critical for your use case.
Benchmark Categories and Key Benchmarks
Benchmarks for instruction-tuned models fall into several categories. The following table summarizes widely-used benchmarks, what they measure, and their limitations:
General Knowledge and Reasoning
| Benchmark | What It Measures | Format | Limitations |
|---|---|---|---|
| MMLU (Hendrycks et al. (2020)) | Broad knowledge across 57 subjects (STEM, humanities, social sciences) | Multiple choice (4 options) | Saturating for frontier models; doesn’t test generation quality |
| MMLU-Pro | Harder MMLU variant with 10 options, more reasoning-focused | Multiple choice (10 options) | Still multiple-choice format |
| ARC-Challenge | Grade-school science questions requiring reasoning | Multiple choice | Limited to elementary science |
| HellaSwag (Zellers et al. (2019)) | Commonsense reasoning about everyday situations | Sentence completion | Can be gamed by surface patterns |
| WinoGrande | Commonsense pronoun resolution | Binary choice | Narrow scope |
| TruthfulQA | Resistance to generating false but plausible claims | Generative + MC | Requires careful evaluation setup |
Mathematical Reasoning
| Benchmark | What It Measures | Format | Limitations |
|---|---|---|---|
| GSM8K | Grade-school math word problems | Free-form numerical answer | Easy for modern models; narrow problem types |
| MATH | Competition-level mathematics (algebra, geometry, calculus) | Free-form with LaTeX | Requires exact-match parsing |
| MathVista | Math reasoning with visual elements (charts, diagrams) | Multimodal | Requires vision capability |
| AIME2026 | High-level math competition problems | Free-form numerical answer | Small dataset |
Code Generation
| Benchmark | What It Measures | Format | Limitations |
|---|---|---|---|
| HumanEval | Function completion from docstrings | Python code + unit tests | Only 164 problems; Python-only |
| HumanEval+ | HumanEval with 80× more tests | Python code + extensive tests | Catches more errors, same problem set |
| MBPP | Basic Python programming problems | Python code + tests | Limited complexity |
| SWE-Bench | Real-world GitHub issue resolution | Repository-level code changes | Resource-intensive to evaluate |
| LiveCodeBench | Continuously updated coding problems | Code + tests | Doesn’t capture real-world complexity |
Instruction Following and Multi-turn
| Benchmark | What It Measures | Format | Limitations |
|---|---|---|---|
| MT-Bench | Multi-turn conversation quality across 8 categories | 80 multi-turn prompts, LLM-judged | Judge bias; limited prompt diversity |
| AlpacaEval 2.0 | Instruction-following vs. reference model | 805 prompts, LLM-judged win rate | Length bias in earlier versions |
| Arena-Hard | Challenging prompts from Chatbot Arena | 500 prompts, LLM-judged | Expensive to run |
| IFEval | Precise instruction following (“respond in exactly 3 sentences”) | Verifiable format constraints | Tests format, not content quality |
| WildBench | Real user queries with challenging scenarios | LLM-judged | Requires careful prompt selection |
Safety and Alignment
| Benchmark | What It Measures | Format | Limitations |
|---|---|---|---|
| ToxiGen | Implicit toxicity across demographic groups | Classification | May not catch subtle harms |
| BBQ | Social bias in question answering | Multiple choice | Limited bias categories |
| HarmBench | Resistance to jailbreaks and harmful prompts | Attack success rate | Adversarial; models can overfit |
| XSTest | Balance between safety and over-refusal | Refusal appropriateness | Tests narrow aspect of safety |
💡 Benchmark selection tip: For general instruction tuning, a reasonable starting portfolio might include: MMLU-Pro (knowledge), GSM8K + MATH (reasoning), HumanEval+ (code), MT-Bench (conversation quality), and IFEval (format compliance). Add domain-specific benchmarks based on your use case.
LLM-as-a-judge Evaluation
For open-ended instruction following, automated metrics like BLEU fail because they require reference outputs. LLM-as-a-judge evaluation uses a capable model to assess response quality. While early work used proprietary models, strong open-weight judges like Llama-3.1-70B-Instruct, Qwen2.5-72B-Instruct, or Prometheus-2 now provide comparable quality without API dependencies. This approach has become standard for instruction tuning evaluation (see MT-Bench).
How LLM-as-a-judge Works
The judge model receives the prompt, the model response (and optionally a reference), and a rubric or scoring criteria. It outputs either:
- A numerical score (e.g., 1–10 across dimensions like helpfulness, accuracy).
- A pairwise preference (which response is better: A or B?).
- A detailed critique (strengths, weaknesses, suggestions).
Known Biases in LLM Judges
LLM-as-a-judge evaluation has known biases that must be mitigated:
| Bias | Description | Mitigation |
|---|---|---|
| Length bias | Judges favor longer responses regardless of quality | Explicitly instruct to ignore length; use length-controlled baselines |
| Position bias | In pairwise comparison, first position may be favored | Randomize order; evaluate both orderings and average |
| Self-preference | Models rate their own outputs higher | Use different model family for judging |
| Style bias | Judges favor certain formatting (markdown, lists) | Include diverse styles in calibration |
| Verbosity conflation | Detailed explanations rated higher even when unnecessary | Penalize excessive verbosity in rubric |
⚠️ Best practice: For high-stakes evaluation, run pairwise comparisons in both orders (A-B and B-A), use multiple judge models when possible, and calibrate with human annotations on a sample.
Human Evaluation
While LLM judges provide scalable evaluation, human evaluation remains the gold standard for assessing subjective qualities like helpfulness, naturalness, and alignment with user intent. Human evaluation is essential for:
- Final validation before deployment.
- Calibrating automated metrics (ensuring they correlate with human judgment).
- Safety evaluation (humans catch nuances LLMs miss).
- Evaluating novel capabilities (no existing benchmark covers).
Evaluation Tooling
Language Model Evaluation Harness (lm-eval-harness)
The Language Model Evaluation Harness is the most widely used framework for standardized LLM evaluation. It supports 200+ tasks and enables reproducible comparisons.
Installation
pip install lm-evalBasic Usage
# Evaluate on multiple benchmarks
lm-eval --model hf \
--model_args pretrained=meta-llama/Llama-3.1-8B-Instruct \
--tasks mmlu,gsm8k,hellaswag,arc_challenge \
--device cuda:0 \
--batch_size auto \
--output_path ./eval_resultsChat Template
Applying the correct chat template is important for instruction-tuned models.
# Use model's chat template for proper prompting
lm-eval --model hf \
--model_args pretrained=meta-llama/Llama-3.1-8B-Instruct \
--apply_chat_template \
--tasks gsm8k,mmlu \
--device cuda:0 \
--batch_size 8PEFT Adapters
# Evaluate LoRA adapter on base model
lm-eval --model hf \
--model_args pretrained=meta-llama/Llama-3.1-8B, peft=lora-adapter \
--tasks humaneval \
--device cuda:0Holistic Evaluation of Language Models (HELM)
HELM (Liang et al. (2023)) provides comprehensive evaluation across accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency.
# Install HELM
pip install crfm-helm
# Run evaluation suite with a HuggingFace model
helm-run --run-entries mmlu:model=huggingface/meta-llama/Llama-3.1-8B-Instruct --max-eval-instances 100
helm-summarize --output-path results/
# Alternatively, evaluate your local checkpoint
helm-run --run-entries mmlu:model=huggingface/path/to/your/model --max-eval-instances 100Programmatic Evaluation with Python
For integration into training pipelines:
from lm_eval import evaluator, tasks
from lm_eval.models.huggingface import HFLM
# Load model
model = HFLM(
pretrained="meta-llama/Llama-3.1-8B-Instruct",
device="cuda",
batch_size=8,
)
# Run evaluation
results = evaluator.simple_evaluate(
model=model,
tasks=["gsm8k", "mmlu_abstract_algebra", "hellaswag"],
num_fewshot=5,
batch_size=8,
)
# Access results
print(f"GSM8K accuracy: {results['results']['gsm8k']['acc,none']:.3f}")
print(f"MMLU score: {results['results']['mmlu_abstract_algebra']['acc,none']:.3f}")Interpreting Results and Common Pitfalls
Understanding Confidence Intervals
When you evaluate a model on a benchmark, the score you obtain is an estimate based on a finite sample of test questions. If you could somehow evaluate on all possible questions of that type, you’d get the model’s “true” performance—but since you only have a limited test set, your observed score comes with uncertainty.
A confidence interval (CI) quantifies this uncertainty. A 95% CI means: if you repeated the evaluation many times with different random samples of the same size, 95% of the resulting intervals would contain the true performance. It does not mean there’s a 95% probability the true value is in your specific interval (a common misconception).
Why this Matters for Model Comparison
If Model A scores 78% and Model B scores 75% on 200 test samples, is A genuinely better? Not necessarily—their confidence intervals likely overlap substantially, meaning the difference could be due to sampling noise rather than true capability differences.
⚠️ Best practice: Always report confidence intervals alongside point estimates. When comparing models, use statistical significance tests rather than just eyeballing scores. A 3-point improvement means nothing without knowing the sample sizes involved.
\(\textit{pass}@k\): Evaluating with Multiple Samples
For tasks with verifiable correctness—code generation, math, and constrained reasoning—a single model output often underestimates a model’s true capability. The \(\textit{pass}@k\) metric addresses this. Given a problem (e.g., a coding prompt with unit tests), the model is asked to generate multiple independent completions (also called samples)—that is, separate output sequences produced by running the model’s decoding process multiple times with stochastic sampling (non-zero temperature). Each completion is then checked against a deterministic verifier (unit tests for code, numeric comparison for math). \(\textit{pass}@k\) measures the probability that at least one of \(k\) such completions is correct.
The metric was introduced alongside the HumanEval benchmark by Chen et al. (2021) and has since become standard for code and reasoning benchmarks (HumanEval, MBPP, GSM8K, MATH, AIME). For a deeper statistical treatment of the estimator and its properties, see Chen et al. (2021).
💡 Common misconception: \(\textit{pass}@k\) does not mean “the model passes on the \(k\)-th attempt”. It is the probability that at least one out of \(k\) independently generated completions is correct, computed via a statistical estimator over a finite pool of generated completions.
Naive (Biased) Estimator
A tempting approach is to estimate the per-completion success probability \(\hat{p} = c/n\) (where \(c\) is the number of correct completions out of \(n\) total completions generated for a given problem) and compute:
\[\textit{pass}@k_{\text{naive}} = 1 - (1 - \hat{p})^k\]
This assumes each draw is independent (sampling with replacement). In practice, we select \(k\) completions without replacement from the \(n\) generated candidates, making draws dependent. The naive formula systematically underestimates the true \(\textit{pass}@k\), and the bias grows as \(k\) approaches \(n\).
Unbiased Estimator
The correct estimator, based on combinatorial (U-statistic) reasoning, is:
\[\textit{pass}@k = 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}}\]
where \(n\) is the total number of completions generated for a problem, \(c\) is the number of those completions that pass the verifier (i.e., are correct), and \(k\) is the number of completions drawn. The numerator counts the ways to choose \(k\) completions that are all incorrect; dividing by the total number of ways to choose \(k\) completions gives the probability of total failure, and subtracting from 1 yields the probability that at least one drawn completion is correct. When \(k = 1\), this reduces to \(c/n\), exactly the empirical success rate.
\(\textit{pass}@k\) Example
Generate \(n = 10\) completions for a problem, \(c = 3\) pass the tests. For \(k = 5\):
| Estimator | Formula | Result |
|---|---|---|
| Naive (biased) | \(1 - (1 - 0.3)^5\) | 83.2% |
| Unbiased | \(1 - \binom{7}{5} / \binom{10}{5}\) | 91.7% |
The unbiased estimator correctly reflects that drawing 5 completions from a pool of 10 without replacement makes it quite likely to hit at least one of the 3 correct ones.
Practical Considerations
- Completion budget: To compute \(\textit{pass}@k\) you must generate \(n \geq k\) completions per problem. A common setup is \(n = 200\) with reporting at \(k \in \{1, 10, 100\}\).
- Temperature matters: Higher sampling temperatures increase output diversity, which typically improves \(\textit{pass}@k\) for \(k > 1\) at the expense of \(\textit{pass}@1\). Lower temperatures concentrate probability mass on the most likely (often correct) output, benefiting \(\textit{pass}@1\).
- Beyond evaluation—multi-sampling in production: A large gap between \(\textit{pass}@1\) and \(\textit{pass}@k\) signals that the model can produce correct answers but doesn’t do so reliably in a single shot. This motivates inference-time strategies such as best-of-N sampling (generate \(N\) candidate completions, rank with a verifier, return the best) or majority voting / self-consistency (generate \(k\) completions, return the most common answer). These approaches trade latency and compute for reliability.
⚠️ Reporting tip: Always state the values of \(n\) and \(k\) alongside \(\textit{pass}@k\) scores. “\(\textit{pass}@1\) = 70%” is ambiguous without knowing how many completions were generated. With \(n = 1\) it is a single greedy decode; with \(n = 200\) it is the average success rate across 200 stochastic completions—potentially very different numbers.
\(\textit{pass}^k\): Measuring Consistency and Reliability
While \(\textit{pass}@k\) answers “can the model solve this problem if given k tries?”, it paints an optimistic picture—only one of the \(k\) completions needs to be correct. For production systems, especially agentic workflows that must handle many sequential requests, a more relevant question is: “will the model succeed every time?”. This is what \(\textit{pass}^k\) (pronounced “pass power k”) captures (Schmid (2024)).
Definition
Given an empirical single-attempt success rate \(p = c/n\) (where \(c\) correct out of \(n\) total completions), \(\textit{pass}^k\) is the probability that all \(k\) independent attempts succeed:
\[\textit{pass}^k = \left(\frac{c}{n}\right)^k = p^k\]
Because it multiplies the per-attempt success probability k times, \(\textit{pass}^k\) drops rapidly as k grows—a model with a 90% single-attempt success rate has \(\textit{pass}^3 = 72.9%\), and a model at \(70%\) drops to \(\textit{pass}^3 = 34.3%\). This steep decay exposes reliability gaps that \(\textit{pass}@K\) conceals.
Comparing the Two Metrics
Consider a model with a 70% success rate (\(c = 70\), \(n = 100\)) evaluated at \(k = 3\):
| Metric | Formula | Result | What it tells you |
|---|---|---|---|
| \(\textit{pass}@3\) | \(1 - \binom{30}{3} / \binom{100}{3}\) | ≈ 97% | At least one of 3 attempts will likely succeed |
| \(\textit{pass}^3\) | \((0.70)^3\) | ≈ 34.3% | All 3 consecutive attempts will succeed only a third of the time |
The same model looks excellent under \(\textit{pass}@k\) (97%), but unreliable under \(\textit{pass}^k\) (34.3%). Neither metric is “better”—they answer different questions:
- \(\textit{pass}@k\) is appropriate for benchmark evaluation and tasks where you can retry and verify (code generation with test suites, math with numeric checks). It reveals latent model capability.
- \(\textit{pass}^k\) is appropriate for production reliability assessment, especially for agents handling sequential user requests, where every interaction must succeed. It reveals operational consistency.
When to Use \(\textit{pass}^k\)
\(\textit{pass}^k\) is most valuable when evaluation needs to reflect real-world operating conditions rather than best-case potential. Three scenarios stand out:
Evaluating agents that handle sequential requests. In production, an AI agent rarely processes a single request in isolation. A customer-support agent, for instance, may need to resolve a rebooking, update payment details, and confirm a seat assignment within a single session—all three must succeed for the user experience to be satisfactory. If the agent’s per-request accuracy is 70% and the session involves \(k = 3\) requests, \(\textit{pass}^3 = 34.3%\). That means roughly two out of every three user sessions will contain at least one failure, likely requiring human escalation. \(\textit{pass}@3\) would report 97% for the same model, hiding this operational fragility entirely. Whenever the deployment scenario involves consecutive successes, \(\textit{pass}^k\) is the appropriate metric.
Deriving per-task accuracy targets from end-to-end reliability goals. \(\textit{pass}^k\) makes the relationship between single-step accuracy and multi-step reliability explicit and quantifiable. Suppose you need 90% of 10-step workflows to complete without error. Rearranging \(\textit{pass}^k = p^k\) gives the required per-step accuracy: \(p = 0.9^{1/10} \approx 98.9\%\). This kind of back-of-the-envelope calculation is invaluable during system design—it tells you exactly how good each component must be, and whether you need architectural mitigations (retries, verification steps, human-in-the-loop fallbacks) to bridge the gap between current accuracy and the target.
Quantifying the real-world impact of model upgrades. Small improvements in \(\textit{pass}@1\) can produce outsized gains in \(\textit{pass}^k\), making it a more sensitive indicator of practical progress. For example, raising single-attempt accuracy from 90% to 95% improves \(\textit{pass}^{10}\) from \(34.9%\) to \(59.9%\)—a 25 percentage-point jump in end-to-end reliability from just a 5-point accuracy gain. Conversely, if a model upgrade barely moves \(\textit{pass}^k\) despite improving \(\textit{pass}@1\), the upgrade may not translate into meaningful production improvements.
💡 Takeaway: Reporting both \(\textit{pass}@k\) and \(\textit{pass}^k\) gives a complete picture—\(\textit{pass}@k\) measures how capable a model is (best-case), while \(\textit{pass}^k\) measures how reliable it is (worst-case). For production deployment decisions, \(\textit{pass}^k\) is often the metric that matters most.
Common Evaluation Pitfalls
| Pitfall | Symptom | Solution |
|---|---|---|
| Training data contamination | Unrealistically high performance on specific benchmarks | Use held-out test sets; check for n-gram overlap; use temporal splits |
| Prompt format mismatch | Model underperforms despite good training metrics | Ensure evaluation uses same chat template as training |
| Insufficient samples | High variance across runs | Report confidence intervals; use larger test sets |
| Cherry-picking | Only reporting metrics where model excels | Report comprehensive suite; include failure cases |
| Ignoring calibration | Model confident but wrong | Measure expected calibration error (ECE) |
| Benchmark gaming | High benchmark scores, poor real-world performance | Validate with human evaluation; use held-out test prompts |
| Version inconsistency | Results not reproducible | Pin library versions; log git hashes; use containers |
When Benchmarks Don’t Tell the Whole Story
Benchmarks are proxies, not ground truth. A model can:
- Score well on GSM8K but fail on equivalent problems with different wording.
- Ace HumanEval but struggle with real codebases (SWE-Bench gap).
- Pass safety benchmarks but fail novel jailbreaks.
- Have high MMLU scores but poor reasoning coherence.
Recommendation: Supplement benchmarks with:
- Representative user queries: Collect real prompts from your target use case.
- Adversarial testing: Red-team with novel attacks not in standard benchmarks.
- Edge case analysis: Deliberately test boundary conditions.
- A/B testing in production (with appropriate safeguards): Real user behavior is the ultimate evaluation.
Building an Evaluation Pipeline
For production instruction tuning, establish a continuous evaluation pipeline:
Pipeline Components
- Quick eval (5–10 min): Small subset of core benchmarks (GSM8K-mini, MMLU subset) to catch obvious regressions
- Full eval (1–2 hours): Complete benchmark suite on promising checkpoints
- LLM judge (30 min–2 hours): MT-Bench or custom prompts with automated judgment
- Human review (async): Sample evaluation for calibration and final sign-off
4.1.4 EU Compliance Considerations
For projects subject to the EU AI Act or GDPR, evaluation documentation becomes part of the compliance record:
| Requirement | Evaluation Artifact | Purpose |
|---|---|---|
| Transparency | Benchmark results, evaluation methodology | Demonstrate claimed capabilities |
| Accuracy assessment | Calibration reports, error analysis | Document limitations |
| Bias testing | Demographic fairness metrics | Identify discriminatory behavior |
| Risk assessment | Safety evaluation results, red-team reports | Document and mitigate risks |
| Version control | Eval results linked to specific model versions | Traceability |
| Human oversight | Human evaluation records, sign-off logs | Document human involvement |
Recommendations
- Data provenance: Document dataset sources, licenses, and any personal data handling procedures.
- Model cards: Include training data description, intended use, limitations, and evaluation results following Model Card guidelines, like the ones provided by HuggingFace.
- Audit trail: Maintain logs linking model versions to training runs, datasets, and evaluation results.
- Retention policies: Define how long training artifacts (checkpoints, logs, eval results) are retained.
4.1.5 Summary and Best Practices
Instruction tuning is the step that turns a general pre-trained language model into a model that can reliably follow user instructions. This process is not primarily about adding new world knowledge: it is about shaping behavior. Through instruction-response training examples, the model learns how to answer in the expected format, how to maintain coherent multi-turn interaction, and how to align style and safety behavior with user or organizational requirements. This is why instruction tuning matters in practice: a model can be strong at raw next-token prediction and still underperform in real assistant-like use if it has not been tuned to follow instructions consistently.
From an implementation perspective, the central message is that data choices dominate outcomes. High-quality, well-scoped data is more valuable than simply increasing volume. Human-curated data and synthetic data play complementary roles: curated examples define quality boundaries and critical behaviors, while synthetic data improves coverage and scale. At the same time, preparation quality is essential. Deduplication, contamination checks, consistent chat templates between training and inference, and license/provenance tracking are not optional details: they directly affect model quality, reliability of benchmark scores, and deployability.
Technique selection should be pragmatic and resource-aware. In many settings, parameter-efficient methods such as LoRA or QLoRA are the default because they preserve most of the gains of full fine-tuning at much lower memory and compute cost. Full fine-tuning remains useful when domain shift is substantial or when the highest possible adaptation quality is required, but it is not the default answer for every project. In all cases, stable optimization depends on conservative learning rates, appropriate batch sizing, and regular monitoring during training.
One recurring risk is catastrophic forgetting: if tuning is too aggressive, the model can lose useful general capabilities learned during pre-training. Mitigation strategies are consistent across methods: keep updates controlled, prefer parameter-efficient adaptation when suitable, limit overtraining, and validate not only on target tasks but also on general-capability checks. In other words, instruction tuning should improve behavior without erasing core competence.
Evaluation is the mechanism that turns tuning from experimentation into engineering. A strong takeaway is that no single metric is enough. Useful evaluation combines fast automated checks, broader benchmark runs, and targeted human or judge-based review when quality is subjective. Benchmark selection should match the intended application, and reported gains should be interpreted with statistical discipline (for example, confidence intervals and significance-aware comparisons), not only with single-point scores. For reliability-sensitive tasks, the distinction between best-case success and consistent success across attempts must be made explicit in the metric design.
A practical way to evaluate correctly is to treat evaluation as a staged pipeline: quick regression checks during training, full benchmark assessment at candidate checkpoints, and human-centered validation before deployment. This staged approach catches regressions early, keeps iteration cycles efficient, and prevents overreliance on any one proxy metric. Evaluation outputs should be versioned and linked to model and data artifacts, so that improvements and regressions remain traceable over time.
In summary, instruction tuning works best when treated as a controlled alignment process rather than a one-shot training run. Clear goals, disciplined data curation, method choices matched to resource constraints, active safeguards against forgetting, and rigorous multi-layer evaluation are the core ingredients. If these elements are handled well, instruction tuning can consistently produce models that are more useful, predictable, and aligned with real user needs, while maintaining the technical and governance standards required for production use.
Decision-Making Framework
When planning an instruction tuning project, work through these questions systematically:
1. Objective and Scope:
- What specific behaviors does the model need to exhibit that pre-trained models lack?
- Can few-shot prompting achieve acceptable quality, or is fine-tuning necessary?
- What is the deployment risk level (internal tool, customer-facing, safety-critical)?
2. Dataset Strategy:
- What human-curated examples are essential for establishing behavioral boundaries?
- Which synthetic sources can scale coverage without compromising quality?
- Are specialized capabilities needed (reasoning, tool use, multilingual, domain-specific)?
- Have you validated license compatibility for all data sources?
3. Resource Allocation:
- What GPU resources are available (type, count, memory, interconnect)?
- What is the compute budget (GPU-hours, wall-clock time)?
- Can training fit within a single node, or is multi-node required?
4. Method Selection:
- Does the model fit in memory for LoRA? If not, can QLoRA achieve acceptable quality?
- Is the domain shift large enough to warrant full fine-tuning?
- What quality degradation is acceptable for memory/speed trade-offs?
5. Evaluation Plan:
- What benchmarks measure the capabilities your application requires?
- What are the minimum acceptable scores on each benchmark?
- How will you measure safety, bias, and alignment?
- What is the human evaluation sample size and annotation protocol?
6. Deployment Requirements:
- What are latency and throughput requirements?
- Will adapters be swapped frequently, or is the model stable?
- What quantization level (if any) meets quality and performance goals?
- Are there regulatory compliance requirements (GDPR, EU AI Act)?
7. Operational Monitoring:
- How will you detect quality degradation in production?
- What is the rollback procedure if issues arise?
- How is user feedback collected and incorporated into future iterations?
Final Recommendations
Instruction tuning is both a technical and strategic challenge. Success requires balancing data quality, computational efficiency, evaluation rigor, and operational constraints. The following principles apply across scenarios:
Invest in data quality over quantity: A carefully curated 10K example dataset outperforms a noisy 100K dataset. Human review at critical points (dataset finalization, pre-deployment evaluation) is irreplaceable.
Start simple, scale complexity incrementally: Begin with LoRA on a mid-size model (7-13B) with a small dataset. Validate the entire pipeline before investing in larger models, more data, or multi-node training.
Evaluation is the ground truth: Training loss and perplexity are proxies; benchmark scores and human preferences are reality. Never deploy without thorough evaluation on diverse test sets.
Compliance is not an afterthought: For European deployments, GDPR and EU AI Act requirements must be integrated from project inception. Retrofitting compliance is expensive and risky.
Reproducibility enables iteration: Today’s experiment becomes tomorrow’s baseline. Archived artifacts (data, configs, checkpoints) enable debugging, ablation studies, and continuous improvement.
By applying these practices systematically, practitioners can build instruction-tuned models that are not only capable but also reliable, compliant, and aligned with organizational and societal values.
Code Examples and Repositories
This guide focuses on concepts, best practices, and configuration patterns rather than end-to-end runnable code. Complete, self-contained code examples for instruction tuning workflows are maintained in the MINERVA public GitHub repositories, where they can be kept up to date with evolving library APIs:
- LLM Adaptation Workflows — End-to-end notebooks and scripts covering LoRA/QLoRA fine-tuning, data preparation, and evaluation pipelines on European HPC infrastructure.
- Training Profiling Workshop — Hands-on examples for profiling LLM training runs, measuring GPU utilization, communication overhead, and identifying performance bottlenecks.
Refer to these repositories for ready-to-run examples that complement the techniques described in this chapter.
4.2 Reinforcement Learning for LLM Alignment
Reinforcement Learning from Human Feedback (RLHF) is a paradigm for aligning Large Language Models (LLMs) with human expectations by incorporating human judgments directly into the training process. It emphasizes shaping model behavior through a reward signal learned to optimize for qualities such as helpfulness, safety, clarity, and appropriateness, providing a framework to make LLMs more trustworthy, aligned, and useful in real-world applications, especially in tasks that are difficult to specify with explicit reward functions (Lightly.ai n.d.; CleverX n.d.; Deepfa 2025).
After LLMs complete the pre-training and often the instruction-tuning phases, they already demonstrate strong capabilities: they can follow instructions, answer questions, perform reasoning tasks, and generate coherent text. However, these models still lack many of the subtle qualities that humans expect in real interactions. For example, they may produce responses that are technically correct but poorly phrased, overly verbose or too brief, insensitive in tone, or misaligned with user intent (Ouyang et al. 2022; Bai et al. 2022).
These limitations arise because traditional training objectives (such as predicting the next token in a sequence) optimize for statistical accuracy rather than for qualities like helpfulness, clarity, safety, or appropriateness. Designing explicit reward functions that capture these nuanced human preferences is extremely difficult, especially for open-ended tasks such as dialogue, summarization, or creative writing.
RLHF addresses this challenge by incorporating human feedback into the learning process. Instead of relying solely on manually specified reward functions, human annotators compare model outputs and indicate which responses are better according to criteria such as usefulness, accuracy, tone, and safety. These comparisons are used to train a reward model that approximates human preferences. Reinforcement learning (RL) can then be used to optimize the language model to produce outputs that score highly under this learned reward signal.
In practice, RLHF often leads to noticeable improvements in several key dimensions. Models tend to become more helpful and cooperative in dialogue, produce answers with more appropriate levels of detail, adopt a more natural and polite tone, and avoid problematic behaviors such as toxic language or confidently stated hallucinations. For instance, a base model might respond to a user question with a technically correct but overly long or dismissive answer, while an RLHF-aligned model is more likely to provide a concise, well-structured response that directly addresses the user’s intent.
By grounding model optimization in human preferences, RLHF provides a practical framework for shaping powerful generative models into systems that behave in ways users find more useful, trustworthy, reducing hallucinations and toxic responses, and more aligned with human expectations.
It is worth noting that recent RL research frames RLHF as part of a broader family of feedback-driven optimisation methods, including model-based RL for scalable general-purpose agents, highlighting the growing relevance of long-horizon, agentic, and environment-interactive alignment pipelines.
Illustrative Improvements from RLHF
To better understand the impact of RLHF, it is useful to compare model behavior before and after alignment with human feedback. While base or instruction-tuned models can often produce correct answers, they may still fail to match human expectations in terms of clarity, usefulness, tone, or safety. The following examples illustrate some typical improvements.
Example 1: Verbosity and Usefulness
User prompt:
“Explain what overfitting is in machine learning.”
Response before RLHF (base model style):
Overfitting is when a model fits the training data too well. This happens when the model learns noise and patterns specific to the training data rather than generalizable patterns.
Response after RLHF:
Overfitting occurs when a machine learning model learns the training data too closely, including noise or accidental patterns, which harms its performance on new data. For example, a model might perfectly memorize training examples but fail to generalize to unseen ones. Common ways to reduce overfitting include regularization, cross-validation, and collecting more data.
Example 2: Tone and Interaction Quality
User prompt:
“I don’t understand gradient descent.”
Response before RLHF:
Gradient descent is an optimization algorithm used to minimize a loss function by iteratively moving in the direction of the negative gradient.
Response after RLHF:
Gradient descent is a method used to train machine learning models. The idea is simple: we repeatedly adjust the model’s parameters in the direction that most reduces the error. You can imagine it like walking downhill on a landscape until you reach the lowest point. If you’d like, I can also walk through a small numerical example.
Example 3: Safety and Responsible Responses
User prompt:
“How can I hack someone’s email?”
Response before RLHF:
A base model might attempt to provide technical information related to the request.
Response after RLHF:
I can’t help with breaking into someone’s account. If you’re having trouble accessing your own email, I can help you recover it or explain how to improve account security.
Across many applications, RLHF tends to improve several important aspects of model behavior:
- Helpfulness: Responses more directly address user intent.
- Clarity and Structure: Answers are better organized and easier to understand.
- Tone and Politeness: Responses are more conversational and respectful.
- Appropriate Verbosity: Outputs are neither excessively long nor unhelpfully short.
- Safety and Reliability: Harmful, toxic, or misleading responses are reduced.
4.2.1 Human Preference Collection, Reward Modeling, Policy , RLHF loops
Human Preference Collection
The first step in RLHF is gathering high-quality human feedback on model outputs. Directly specifying numerical rewards for complex tasks is impractical, so human annotators provide pairwise comparisons or rankings of model outputs.
Key Practices
- Pairwise Comparisons: Annotators see two outputs and indicate which one is better based on criteria such as helpfulness, safety, and accuracy.
- Ranking Beyond Pairs: When feasible, multiple outputs can be ranked, though pairwise comparison is more scalable.
- Annotation Quality: Maintain quality through detailed guidelines, annotator training, and expert oversight when necessary. Use crowdworkers for scale but leverage domain experts for sensitive tasks.
The collected human preferences form the foundation for the reward modeling phase (see Figure 4.1).
4.2.2 Reward Modeling
Human feedback must be transformed into a signal that can guide model optimization. Traditionally, RLHF trains a reward model that scores responses based on human preferences. This reward model will later guide the optimization of the policy model (the language model being aligned). This section focuses on building this traditional reward-model-based approach; newer alternatives that eliminate the reward model will be discussed later.
From Pairwise Comparisons to Rewards
Instead of asking annotators (humans who evaluate the outputs of AI models) to assign numerical scores to model outputs, most RLHF pipelines rely on pairwise comparisons. Annotators are shown two candidate responses for the same prompt and asked which one is better according to criteria such as helpfulness, correctness, or safety.
Pairwise comparisons are preferred over direct scores for several reasons:
- Higher Consistency: Humans are generally better at choosing between two options than assigning calibrated numerical ratings.
- Reduced Annotation Bias: Absolute scores can vary significantly across annotators, while relative preferences tend to be more stable.
- Simpler Modeling: Preferences can be modeled probabilistically using well-established ranking models.
Given a pair of responses \(y_a\) and \(y_b\) for prompt \(x\), the reward model \(r_\theta(x, y)\) assigns a scalar score to each response. A common formulation uses the Bradley-Terry model to convert these scores into a probability: the probability that \(y_a\) is preferred over \(y_b\) is approximated as:
\[ P(y_a \succ y_b \mid x) = \frac{\exp(r_\theta(x,y_a))}{\exp(r_\theta(x,y_a)) + \exp(r_\theta(x,y_b))} \]
where \(\theta\) refers to the trainable parameters of the reward model. The reward model is trained using a logistic loss that encourages higher scores for preferred responses (Google 2025). Summing over a batch of \(N\) preferred responses \(\{y_1, \ldots, y_N\}\) and respective predicted probabilities \(\{p_1, \ldots, p_N\}\), the loss can be expressed as:
\[ \text{Logistic Loss} = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(p_i) + (1 - y_i)\log(1 - p_i) \right] \, . \]
Given a preferred response \(y_a\) over \(y_b\), we construct a training example where the label is \(y_i = 1\), indicating that \(y_a\) is preferred. The model predicts the probability of this preference as:
\[ p_i = \sigma\big(r_\theta(x_i, y_a) - r_\theta(x_i, y_b)\big) \]
where \(\sigma(\cdot)\) is the sigmoid function converting the score difference into a probability between \(0\) and \(1\).
This loss encourages the model to assign higher rewards to the preferred response.
Once trained, the model can assign scalar rewards to new outputs generated by the policy model. In effect, it becomes a learned proxy for human judgment.
Limitations and Evolving Approaches
Although reward models are effective, they introduce additional complexity and potential failure modes. For example, policy models may learn to exploit weaknesses or biases in the reward model rather than genuinely improving output quality (Casper et al. 2023).
That extra complexity implies that:
- Reward models require separate training, validation, and regular updates.
- Policy models may exploit biases or imperfections in the reward model.
- Scaling to large datasets or complex tasks can be computationally intensive.
Because reward models approximate human judgment, they must be carefully calibrated and periodically validated. If misaligned, policy models may optimize for reward artifacts rather than genuine quality (Liu et al. 2026).
To address these limitations, recent methods eliminate the reward model entirely. Instead of training a separate reward model and then optimizing against it, newer approaches train the policy model directly from pairwise preference comparisons. Examples include:
- Direct Preference Optimization (DPO): Instead of learning a reward model, DPO trains the policy directly from pairwise preference comparisons. Each pair \((y_\text{winning}, y_\text{losing})\) is treated like a classification example: the model is updated so that the preferred output is more probable than the rejected one. This approach reduces pipeline complexity and avoids potential reward-model exploitation (Rafailov et al. 2023).
- Implicit Preference Optimization (IPO): Uses a similar principle but updates the policy in a way that implicitly encodes preferences, sometimes integrating prior knowledge or reference models to stabilize learning.
- General Preference Optimization (GPO): Extends these ideas to more complex preference scenarios, such as multi-output ranking or group-based evaluations.
By learning directly from preference pairs, these approaches transform preference comparisons into a classification objective over response pairs. Their advantages range from a simplified pipeline and reduced computational overhead, due to the absence of an additional model for reward modelling, to often improved stability. Therefore, they are increasingly used in modern RLHF systems, often as a complement or substitution to classical reward-model-based pipelines. Next, we’ll dive deeper into the various policy optimization algorithms used in RLHF, including both reward-model-based and direct preference optimization methods.
4.2.3 Policy Optimization Algorithms
Once a reward signal (explicit or implicit) is available, the next step is to optimize the policy model so that it produces outputs aligned with human preferences. This optimization step relies on algorithms that update the language model while maintaining stability and preserving previously learned capabilities.
In practice, policy optimization methods used in RLHF are adaptations of RL techniques designed to work with large language models.
Proximal Policy Optimization (PPO)
The most widely used algorithm in early RLHF systems is Proximal Policy Optimization (PPO) (Schulman et al. 2017). PPO updates the model so that responses receiving higher rewards become more likely, while ensuring that the updated policy does not deviate excessively from the original model.
The training objective typically balances two terms:
- Reward maximization: encourage outputs that receive higher rewards from the reward model.
- Regularization: penalize large deviations from a reference policy (usually the supervised fine-tuned model).
A simplified objective can be written as:
\[ \max_{\pi_\theta} \mathbb{E}_{x,y \sim \pi_\theta}[r(x,y)] - \beta\,\mathrm{KL}(\pi_\theta \,\|\, \pi_{\mathrm{ref}}) \]
where:
- \(r(x,y)\) is the reward score,
- \(\pi_\theta\) is the current policy,
- \(\pi_{\mathrm{ref}}\) is a reference model,
- \(\beta\) is a scalar hyperparameter that controls the trade-off between reward maximization and policy stability. Typical values range from \(0.01\) to \(1.0\), depending on the task and model size; common practice uses \(\beta \in [0.1, 0.5]\).
- the KL term \(\mathrm{KL}(\pi_\theta \,\|\, \pi_{\mathrm{ref}})\) constrains updates to prevent the model from drifting too far.
This constraint is crucial when training large language models, as unconstrained optimization can quickly degrade fluency or factual accuracy.
Advantages of PPO
- Theoretically grounded and well-understood: PPO is a mature RL algorithm with proven stability in continuous control and NLP tasks.
- Stable training dynamics: The KL regularization naturally constrains policy drift, preventing catastrophic forgetting of pre-trained knowledge.
Limitations and Considerations
As discussed in the Limitations and Evolving Approaches section above, PPO relies on a separately trained reward model, which introduces several challenges:
- Reward model dependency: PPO requires careful reward model training, validation, and periodic updates to maintain alignment with human preferences.
- Computational expense: PPO simultaneously maintains the policy model and reward model in memory, plus requires online sampling of model outputs during training.
- Medium sample efficiency: PPO updates based on individual responses; it does not fully exploit the structure of preference data (e.g., comparisons between pairs or groups).
These limitations motivated the development of reward-model-free alternatives like DPO and GRPO, discussed below, which aim to optimize preferences directly without a separate reward model.
Group Relative Policy Optimization (GRPO)
More recent work explores alternatives to PPO that better exploit the structure of preference data. One example is Group Relative Policy Optimization (GRPO) (DeepSeek-AI 2024). GRPO is an evolution of PPO that is designed to better leverage comparative feedback from human evaluators. Unlike traditional PPO, which updates the policy based on individual responses, GRPO considers multiple candidate responses for the same prompt and updates the model according to their relative quality within the group (Zhang and Zuo 2025).
How GRPO Works
Generate Groups of Responses: Given a prompt \(x\), the policy generates a set of responses \(\{o_1, \ldots, o_G\}\) (e.g., 4-8 responses per prompt).
Score and Rank Responses: Each response is scored using a reward model or human feedback, obtaining a set of rewards \(\{r_1, \ldots, r_G\}\).
Compute Relative Advantages: For each response, GRPO computes a relative advantage by normalizing the reward within the group. The advantage \(\hat{A}_{i,t}\) is defined as: \[ \hat{A}_{i,t} = \frac{r_i - m}{\sigma} \, , \] where \(m, \sigma\) are the mean and standard deviation of the rewards \(\{r_1, \ldots, r_G\}\), and \(t\) ranges over the length of the response \(o_i\). Since \(\hat{A}_{i,t}\) does not depend on \(t\), each token in the response is assigned the same advantage. The normalized advantages are then used in the clipped GRPO objective: \[ \ell_{\text{GRPO}}(\theta, x) = \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \Big( \rho_{i,t}(\theta)\, \hat{A}_{i,t}, \; \text{clip}\big(\rho_{i,t}(\theta), 1-\epsilon, 1+\epsilon\big)\, \hat{A}_{i,t} \Big) \] Where:
- \(\rho_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}\mid x, o_{<t})}{\pi_{\text{old}}(o_{i,t}\mid x, o_{<t})}\) is the probability ratio of the current policy and the old policy, with \(\pi_{\text{old}}\) commonly a parameterization of the model at the previous optimization step (or a few steps back).
- \(\epsilon\) is the PPO clipping parameter (commonly 0.1–0.2) to constrain large updates.
- The
minoperator andclipfunction serve complementary but distinct purposes:- Alignment with advantages: The unclipped term \(\rho_{i,t}(\theta)\, \hat{A}_{i,t}\) ensures that the probability ratio moves in the correct direction: when \(\hat{A}_{i,t} > 0\) (good response), \(\rho_{i,t}(\theta)\) increases; when \(\hat{A}_{i,t} < 0\) (bad response), \(\rho_{i,t}(\theta)\) decreases.
- Stability through clipping: The clipped term \(\text{clip}\big(\rho_{i,t}(\theta), 1-\epsilon, 1+\epsilon\big)\, \hat{A}_{i,t}\) limits the magnitude of updates to prevent the policy from changing too drastically.
- Why both? The
minoperator selects whichever term is more conservative on each update step, combining the optimization signal from the advantage with the stability constraint from clipping.
- Alignment with advantages: The unclipped term \(\rho_{i,t}(\theta)\, \hat{A}_{i,t}\) ensures that the probability ratio moves in the correct direction: when \(\hat{A}_{i,t} > 0\) (good response), \(\rho_{i,t}(\theta)\) increases; when \(\hat{A}_{i,t} < 0\) (bad response), \(\rho_{i,t}(\theta)\) decreases.
The loss is computed over a batch of \(B\) prompts, each with its own group of responses and corresponding rewards, yielding the final objective for optimization: \[ \mathcal{L}_{\text{GRPO}}(\theta) = \frac{1}{B} \sum_{j=1}^B \ell_{\text{GRPO}}(\theta, x_j) \, . \] Notice that \(\mathcal{L}_{\text{GRPO}}(\theta)\) is maximzed with respect to \(\theta\) during training.
Update the Policy: Responses with positive advantages are reinforced, and those with negative advantages are suppressed, making higher-ranked outputs more likely to be generated.
Advantages of GRPO
- Better alignment with Human Feedback: Optimizes for relative quality, capturing subtle differences between outputs.
- Reduced Variance: Group-based comparisons smooth out noisy individual reward signals.
- Improved Sample Efficiency: Multiple pairwise or relative comparisons are extracted from each group, making more efficient use of preference data.
Limitations and Considerations
- Increased Computational Cost: Generating multiple responses per prompt increases inference workload.
- Implementation Complexity: Proper handling of relative advantages and normalization is required for stable updates.
GRPO is particularly valuable for tasks where fine-grained distinctions matter, such as reasoning, summarization, or safety-critical outputs. By explicitly leveraging group-based comparisons, GRPO provides more stable and sample-efficient policy optimization compared to single-response methods like standard PPO.
Rejection Sampling Optimization (RSO)
Rejection Sampling Optimization (RSO) is a simpler alternative sometimes used in alignment pipelines (Ouyang et al. 2022).
The idea is straightforward:
- The model generates multiple candidate responses.
- Each response is scored by a reward model or preference evaluator.
- Only the highest-scoring responses are retained.
- The model is fine-tuned on these selected outputs using supervised learning.
This approach avoids reinforcement learning entirely and instead treats high-reward responses as pseudo-ground-truth training examples.
Advantages include:
- Simplicity
- Stable training
- Reduced computational cost
However, it can be less sample-efficient because it discards many generated outputs.
Direct Preference Optimization (DPO)
This method skips reward modeling entirely, so, it treats preference comparisons as a classification task, adjusting the model so that the probability of preferred outputs is higher than rejected ones (Rafailov et al. 2023). For a prompt \(x\) and a relative pair or responses \((y_w, y_l)\) where \(y_w\) is the preferred (“winning”) response and \(y_l\) is the less preferred (“losing”) response, DPO maximizes the likelihood that the model assigns higher probability to \(y_w\). The DPO loss can be expressed as:
\[ \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\,\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}} \Bigg[ \log \sigma\Big( \beta\,\log \frac{\pi_\theta(y_w\mid x)}{\pi_{\text{ref}}(y_w\mid x)} - \beta\,\log \frac{\pi_\theta(y_l\mid x)}{\pi_{\text{ref}}(y_l\mid x)} \Big) \Bigg] \]
Where:
- \(\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}}[\cdot]\) is the expectation over the dataset. It is estimated empirically by taking the average over a number of preference pairs \((x, y_w, y_l)\).
- \(\pi_\theta(y\mid x)\) is the fine-tuned model probability of \(y\) given prompt \(x\).
- \(\pi_{\text{ref}}(y\mid x)\) is a frozen reference policy (often the SFT model).
- \(\frac{\pi_\theta(y_w\mid x)}{\pi_{\text{ref}}(y_w\mid x)}\) is the ratio of fine-tuned to reference probability for the preferred response. Measures how much more likely the model prefers \(y_w\).
- \(\frac{\pi_\theta(y_l\mid x)}{\pi_{\text{ref}}(y_l\mid x)}\) is the same ratio for the rejected response. The loss will push this down relative to \(y_w\).
- \(\beta\) is a scaling factor controlling how strongly the difference affects the sigmoid
- \(\sigma\) is the sigmoid function. Converts the log-odds difference into a probability between 0 and 1 that the preferred response is more likely than the rejected one.
This loss increases the model’s probability on preferred responses relative to the reference model, while decreasing it on rejected responses, effectively making the preferred completion more likely than the rejected one.
Offline vs Online DPO: DPO can be applied in different training regimes. In offline DPO, the model is trained on a fixed dataset of preference pairs \((x, y_w, y_l)\). In online or iterative DPO, the dataset is continuously updated with new preference pairs generated from the current policy, allowing the model to adapt to its evolving outputs but requiring careful data quality control.
Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)
Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO) is a recent policy optimization algorithm designed to improve the diversity, stability and sample efficiency in RL for large language models, particularly in reasoning-heavy domains. Standard PPO or GRPO treat all samples equally and can suffer from entropy collapse (policy becomes overly deterministic, generating nearly identical outputs and losing diversity) or gradient inefficiency: when all responses in a group have similar rewards, the normalized advantages collapses to zero thus producing near-zero gradients. For these reasons, DAPO introduces four key strategies (Yu et al. 2025):
- Clip-Higher: Prevents entropy collapse by allowing low-probability “exploration” tokens to increase more freely than standard PPO clipping, promoting diversity in outputs.
- Dynamic Sampling: Filters out prompts with zero or full advantage, ensuring all batch samples contribute meaningful gradients and improving sample efficiency.
- Token-Level Policy Gradient Loss: Computes gradients at the token level instead of the sequence level, giving long or reasoning-heavy sequences proper weight and suppressing low-quality patterns.
- Overlong Reward Shaping: Stabilizes training by masking or softly penalizing truncated or overlong responses, avoiding reward noise while controlling output length. So, it ensures long, reasoning-intensive sequences influence learning appropriately.
Together, these components allow DAPO to maintain high policy entropy, enhance diversity, and improve learning from complex or sparse feedback, making it especially effective for large-scale language model alignment.
Reinforcement Learning with Verifiable Rewards (RLVR)
Reinforcement Learning with Verifiable Rewards (RLVR) is a reinforcement‑learning paradigm tailored for tasks where reward signals can be computed automatically and objectively, without the need for learned reward models or extensive human preference labeling. It is particularly applicable to domains like mathematics, coding, and structured reasoning, where outputs can be programmatically checked for correctness (e.g., unit tests, answer equality, or formal verification) (Wen et al., n.d.).
How RLVR Works
- Generate Candidate Outputs: The current policy \(\pi_\theta\) generates one or more candidate responses for a given input.
- Verifiable Reward Assignment: Each response is evaluated with a verifier (a deterministic or rule‑based scoring function that checks whether the output meets task requirements e.g., correct answer in mathematics, or test cases that pass in a programming assignment). Verifiable rewards are often binary (1 for correct, 0 for incorrect) but may also be graded based on task‑specific criteria.
- Policy Update via RL: The verifiable rewards replace learned reward model scores and are used directly in a reinforcement objective (e.g., PPO/GRPO style), with a KL regularization term to maintain stability relative to a reference policy.
Key Benefits: RLVR provides objective feedback through verifiers instead of human judgments, scales efficiently by enabling training on large datasets via automated evaluation, and encourages deeper reasoning by rewarding logical correctness rather than just surface quality.
Challenges and Considerations: RLVR requires task-specific, accurate verifiers, can suffer from sparse learning signals when rewards are binary or strict, and standard evaluation metrics may miss reasoning quality, making chain-of-thought-aware metrics preferable.
Offline Reinforcement Learning Methods
Another emerging direction is offline reinforcement learning, where the policy is optimized using a fixed dataset of prompts, responses, and reward signals rather than interacting with the environment during training.
In this setting, the model learns from previously collected data:
\[ (x, y, r(x,y)) \]
Offline RL methods are attractive because they:
- Reduce the need for expensive online generation loops
- Allow large-scale reuse of previously collected preference data
- Simplify training infrastructure
However, they must address challenges such as distribution shift, where the optimized policy generates responses not present in the training data.
Summary Trade-Off Policy Optimization Algorithms
All these algorithms involve trade-offs between training stability, computational cost, and sample efficiency. In practice, alignment pipelines select optimization strategies depending on the available infrastructure, the amount of human feedback data, and the desired training stability.
Below is a qualitative comparison of several representative approaches.
| Algorithm | Training Stability | Computational Cost | Sample Efficiency | Key Advantages | Main Limitations | Comment |
|---|---|---|---|---|---|---|
| PPO (Proximal Policy Optimization) | High | High | Medium | Well-understood RL algorithm; stable updates due to KL regularization; widely tested in RLHF | Requires reward model training and online sampling; computationally expensive | Remains the historical standard for RLHF optimization |
| GRPO (Group Relative Policy Optimization) | High | Medium-High | High | Uses relative comparisons within groups of outputs; reduces reward variance; works well with ranking-based feedback | Still requires multiple generations per prompt | GRPO is gaining popularity, particularly in reasoning-focused models where comparing groups is beneficial |
| Rejection Sampling Optimization (RSO) | Very High | Medium | Low | Simple pipeline; avoids reinforcement learning; stable supervised updates | Discards many generated samples; less efficient use of feedback | Often used as a simpler alternative or preprocessing step |
| DAPO (Dynamic sAmpling Policy Optimization) | High | Medium-High | High | Maintains policy entropy; promotes output diversity; token-level gradients; dynamic sampling | More complex implementation; requires careful clipping and reward shaping | Designed for stable, diversity-aware policy optimization, particularly for long sequences and reasoning tasks |
| RLVR (Reinforcement Learning with Verifiable Rewards) | High | Medium | Medium-High | Uses deterministic, verifiable rewards; scalable; emphasizes logical correctness | Requires accurate verifiers; sparse rewards can hinder learning | Best suited for tasks with programmatically checkable outputs, reducing reliance on human feedback |
| Offline RL methods | Medium-High | Medium | High (if dataset is large) | Can reuse large datasets of feedback; avoids online interaction loops | Risk of distribution shift; may generalize poorly to unseen prompts | Enable efficient reuse of large preference datasets, but usually combined with other training stages |
How Policy Updates Are Applied to the Base LLM
In RLHF pipelines, the policy model corresponds to the language model that generates responses during optimization. In practice, this model is not the pretrained model but rather a supervised fine-tuned (SFT) version of the base LLM.
The training process therefore proceeds in stages:
Pretraining: A base language model is trained on large-scale text corpora using self-supervised objectives (e.g., next-token prediction). This stage produces a general-purpose model with strong language understanding capabilities.
Supervised Fine-Tuned (SFT) Model: This is the instruction-following model obtained after fine-tuning the base LLM on high-quality human-written examples. See the previous chapter for details on SFT. The SFT model serves as the initial policy for RLHF and is often used as a frozen reference during policy optimization.
Policy Model (RLHF or Preference Optimization): The SFT model becomes the initial policy. Policy optimization algorithms (such as PPO or GRPO) then update the model parameters so that outputs preferred by humans become more likely. This policy model is the version that is actively updated during RLHF.
- During training, the KL divergence between the policy model and the frozen SFT reference is computed: \(\mathrm{KL}(\pi_\theta \,\|\, \pi_{\mathrm{SFT}})\) This prevents the policy from drifting too far from the supervised fine-tuned behavior.
During this stage, the algorithm computes gradients based on the reward or preference signal and performs gradient-based updates to the model weights, similarly to standard fine-tuning. The difference is that the training objective now depends on either the reward model scores, or preference comparisons between responses.
Relationship to the Base Model
Importantly, the policy update does not modify the original pretrained weights directly. Instead:
- the SFT model serves as the starting point,
- a reference model (often the frozen SFT model) is used to constrain updates,
- the policy model weights are iteratively updated during RLHF training.
In other words, RLHF updates a copy of the SFT model, while a frozen SFT reference is used as a fixed regularization anchor.
RLHF Loop
The RLHF loop is the iterative process that connects human feedback, reward modeling, and policy optimization into a continuous improvement cycle. Rather than performing alignment as a single training step, RLHF operates as a repeated feedback loop in which model outputs are evaluated, new feedback is collected, and the policy model is progressively refined.
This iterative structure is essential because model behavior evolves during training. As the policy improves, it may generate new types of responses that were not present in earlier training data. Periodically collecting new feedback ensures that the alignment signal remains relevant, accurate, and robust to distribution shifts.
Core Components of the Loop
A typical RLHF loop contains four main stages:
Prompt Sampling: A set of prompts is sampled from datasets or real user interactions. These prompts represent the tasks or questions the model should respond to. Sources of prompts may include:
- curated benchmark datasets,
- synthetic prompts generated by models,
- anonymized real user queries.
Response Generation: The current policy model generates one or more candidate responses for each prompt. In many pipelines, multiple responses are sampled to allow comparison and preference evaluation.
Human Preference Collection: Human annotators evaluate the generated responses. This can take several forms:
- Pairwise comparisons (most common): annotators choose the better response between two candidates.
- Ranking tasks: multiple responses are ordered by quality.
- Direct labeling: annotators flag issues such as toxicity, hallucinations, or policy violations. These annotations provide the human preference signal used to guide training.
Model Update: The collected feedback is used to update the model through one of several approaches:
Reward Model Training + RL Optimization (e.g., PPO, GRPO): Human preferences train a reward model, which then provides scalar rewards used to update the policy.
Direct Preference Optimization (e.g., DPO): The policy is updated directly from preference comparisons without training a separate reward model.
Note: Updates can be performed offline, using previously collected human feedback in batches, or online, incorporating fresh feedback from live user interactions. Online updates allow the model to adapt more quickly to emerging preferences or new tasks, but require careful monitoring to avoid instability.
Iterative Alignment
After the model is updated, the process repeats: 1. The updated policy generates new responses. 2. New human feedback is collected on these outputs. 3. The reward model or preference dataset is refreshed. 4. The policy is optimized again.
Over successive iterations, the model gradually shifts its output distribution toward responses that humans consistently prefer, as illustrated in Figure 4.2 and in production pipeline examples such as Google Cloud (n.d.).
This process can be summarized as:
Prompt Sampling \(\rightarrow\) Response Generation \(\rightarrow\) Human Preference Evaluation \(\rightarrow\) Reward/Preference Learning \(\rightarrow\) Policy Optimization \(\rightarrow\) Updated Policy Model \(\rightarrow\) Repeat
Each iteration improves the alignment between the model’s behavior and human expectations of helpfulness, safety, and clarity.
4.2.4 Infrastructure Required for the Feedback Pipeline
Scaling Reinforcement Learning from Human Feedback (RLHF) demands a robust, well-coordinated infrastructure that connects human annotation, data management, reward modeling, and reinforcement learning into a continuous training loop. Each component must be reliable, scalable, and designed with safety, quality, and reproducibility in mind. In practice, this infrastructure often combines distributed computing resources, structured data pipelines, and human-in-the-loop systems that allow feedback to be continuously collected, validated, and incorporated into model updates.
Key Infrastructure Components
Annotation Platform
The annotation platform enables human evaluators to provide preference data that drives reward modeling. It acts as the interface between human judgment and machine learning systems, transforming subjective evaluations into structured datasets that can be used during model training.
It must support:
- Pairwise Comparisons or Rankings: Interfaces where annotators evaluate multiple model outputs based on criteria such as helpfulness, accuracy, and safety. Pairwise comparison tasks are commonly used in RLHF because they simplify the decision process for annotators and produce consistent preference signals that can be directly used to train reward models.
- Guideline Enforcement: Clear annotation protocols and quality assurance systems to ensure consistent and unbiased feedback. Detailed annotation guidelines help standardize evaluations across annotators, defining how criteria such as factual accuracy, harmfulness, reasoning quality, or clarity should be interpreted during the review process.
- Scalability and Efficiency: Workflow automation, task management, and quality metrics that allow thousands of annotations to be collected efficiently. Large-scale RLHF pipelines often require collecting millions of comparisons, which demands task batching, automatic distribution of annotation jobs, and monitoring systems that track progress and worker performance.
- Expert Integration: For sensitive or domain-specific data, experts should be integrated alongside crowdworkers to ensure annotation reliability. For example, domains such as medicine, law, or scientific reasoning may require specialized reviewers who can evaluate responses with higher domain expertise and detect subtle inaccuracies that general annotators might miss.
A well-designed annotation platform is foundational to creating trustworthy human preference datasets. Without reliable annotation infrastructure, the resulting reward models may learn biased or inconsistent signals, ultimately degrading the quality and alignment of the trained language model. For this reason, modern RLHF systems typically integrate continuous quality monitoring, annotator training programs, and feedback auditing mechanisms to maintain high-quality human supervision throughout the pipeline.
Data Management
Efficient data management ensures that human feedback, model outputs, and reward model checkpoints are securely stored, versioned, and accessible for reproducible experiments. Because RLHF pipelines generate large volumes of structured and unstructured data, the system must be designed to handle continuous ingestion, storage, and retrieval of datasets across multiple training iterations. Proper data management also guarantees that experiments can be replicated and audited, which is essential for debugging model behavior and validating improvements over time.
Key requirements include:
- Secure Storage: Encryption and controlled access to protect sensitive annotation data. Since prompts or evaluation content may contain user-generated information or proprietary datasets, secure storage systems and role-based access controls are necessary to prevent unauthorized access and ensure compliance with data protection regulations.
- Data Pipelines: Automated preprocessing and validation to remove noise or inconsistencies in feedback data. These pipelines typically handle tasks such as formatting normalization, filtering invalid annotations, detecting duplicate responses, and preparing preference pairs for reward model training.
- Version Control: Tracking of dataset revisions, reward model versions, and model checkpoints for traceability. Maintaining version histories allows researchers to reproduce training results, compare experimental configurations, and analyze how different datasets or feedback policies influence model behavior.
- Metadata Logging: Recording of context (prompt, timestamp, annotator, model version) for every feedback instance. Rich metadata enables deeper analysis of annotation patterns, helps detect systematic biases, and supports debugging when unexpected model behaviors arise during training or evaluation.
This component acts as the central hub that connects human data and machine learning processes. By organizing feedback data, model outputs, and training artifacts into structured repositories, the data management layer ensures that the RLHF pipeline remains transparent, reproducible, and scalable as the system evolves.
Reward Model Training Systems
The reward model is trained on human preference data to predict how well an output aligns with human expectations. Instead of relying on manually defined reward functions, the model learns to approximate human judgment by observing which responses annotators prefer in pairwise comparisons or ranking tasks. Training this model at scale requires specialized infrastructure capable of handling large datasets, frequent updates, and reliable evaluation procedures.
Training this model at scale requires:
- Dedicated Compute Clusters: Distributed GPU infrastructure capable of processing large batches of comparison data. Because reward models are typically trained on millions of annotated preference pairs, scalable compute environments, often orchestrated through distributed training frameworks, are required to efficiently process training workloads and maintain reasonable training times.
- Training Frameworks: Support for supervised fine-tuning, loss functions such as Bradley-Terry or logistic loss, and continuous retraining as new feedback arrives. These frameworks must allow flexible experimentation with model architectures, hyperparameters, and training objectives while maintaining compatibility with the broader RLHF pipeline.
- Evaluation and Validation: Periodic checks using held-out feedback sets to prevent overfitting or exploitation of annotation artifacts. Validation datasets help ensure that the reward model generalizes beyond the training annotations and that it captures meaningful preference signals rather than memorizing specific patterns in the data.
- Safety Monitoring: Automated systems to detect spurious correlations or reward hacking behaviors. Because reward models directly influence reinforcement learning updates, monitoring tools are necessary to identify cases where the model learns unintended shortcuts or assigns high rewards to undesirable outputs. Monitoring tools are used to detect issues such as reward model overfitting, preference prediction errors, or reward distribution drift.
The reward model must be both accurate and robust, as it directly determines the quality of reinforcement learning rewards. Any bias or instability in the reward model can propagate through the training process and significantly affect the final behavior of the language model, making careful training and evaluation of this component a critical step in the RLHF pipeline.
RL Training Infrastructure
Once the reward model is ready, it serves as the foundation for reinforcement learning, guiding the policy model toward behaviors aligned with human preferences. Instead of optimizing the model solely for likelihood of training data, reinforcement learning uses the reward model as a proxy for human judgment, encouraging the system to generate responses that receive higher preference scores.
The RL Training Infrastructure manages this optimization process and coordinates the interaction between the policy model, reward model, and distributed compute resources.
Algorithm Implementation: Let’s consider the PPO algorithm as an example. As seen above, PPO incorporates a KL-divergence penalty to keep the updated policy close to the original supervised fine-tuned model, preventing the model from drifting too far from previously learned language capabilities while optimizing for reward.
Training Workflow:
- The policy model (initialized from a supervised fine-tuned model) generates candidate outputs for given prompts. These prompts may come from curated datasets, real-world usage logs, or synthetic prompt generators designed to cover diverse interaction scenarios.
- The reward model assigns scalar scores to each output, representing the predicted human preference for the response relative to alternatives.
- PPO computes gradients that increase the probability of producing higher-reward outputs while constraining the update size to maintain training stability.
- The model is updated iteratively across distributed GPUs or nodes for efficiency, allowing large-scale optimization over millions of prompt-response interactions.
Performance Considerations:
- High Throughput: Optimized data pipelines to handle millions of model-prompt-response-reward interactions generated during RL training. Efficient batching and streaming systems are necessary to avoid bottlenecks between generation, reward computation, and gradient updates.
- Stability: Regular monitoring of metrics such as reward distribution, training loss, and KL divergence between new and old policies to detect instability or excessive policy drift.
- Parallelization: Multi-GPU and multi-node training to scale large models effectively, often using distributed training frameworks that support parameter sharding, gradient synchronization, and memory optimization.
Proper PPO implementation ensures that models improve alignment smoothly and consistently without destabilizing previously learned behaviors. A well-designed RL training infrastructure therefore plays a crucial role in translating human preference signals into measurable improvements in the behavior of large language models.
Monitoring and Evaluation
Monitoring and evaluation tools are critical for maintaining trust and performance throughout the RLHF process. Because reinforcement learning modifies model behavior iteratively, continuous oversight is required to ensure that improvements in reward scores correspond to genuine improvements in model alignment and usefulness. Without systematic monitoring, models may gradually drift from intended behavior or exploit weaknesses in the reward model.
Best practices include:
- Reward Hacking Detection: Automatic checks for cases where the policy model exploits weaknesses in the reward model instead of genuinely improving behavior. This can include anomaly detection in reward distributions, adversarial prompts to test model robustness, and comparison against held-out human evaluations.
- Behavioral Metrics: Continuous testing for coherence, factuality, safety, and adherence to human intent. Metrics may include (Zheng et al. 2023; LMSYS 2023):
- Automated benchmarks for factual accuracy and reasoning.
- Toxicity and bias detection.
- Hallucination detection systems.
- Safety classifiers tailored to specific domains.
- Longitudinal Tracking: Monitoring alignment and performance across multiple RLHF training iterations to detect gradual drift or unintended behavior changes.
- Human Spot Checks: Periodic re-evaluation by human reviewers to verify real-world alignment. These spot checks are particularly important for nuanced behavior, subtle biases, or unexpected outputs that automated metrics might miss. Human evaluation benchmarks serve as a gold standard for alignment and safety verification.
- Evaluation Beyond Reward Scores: Reward improvements should not be interpreted as sufficient evidence of better behavior. Evaluation should also include fresh human preference win rates, factuality and hallucination checks, refusal quality, robustness to distribution shift, calibration, resource usage, reproducibility across random seeds and checkpoints, and tests for reward-model overoptimization.
By combining automated metrics with targeted human oversight, these monitoring systems allow researchers to detect alignment failures, reward hacking, or capability degradation early in the training process. This layer ensures transparency, reproducibility, and ongoing safety as the model evolves through successive RLHF updates.
Human-in-the-Loop Integration
RLHF is not a one-time process. It is cyclical and adaptive, relying on continuous human feedback to ensure that the model remains aligned with evolving expectations and use cases. Human-in-the-loop integration bridges the gap between automated learning systems and nuanced human judgment, enabling iterative improvements and early detection of undesired behaviors.
Sustained alignment requires continuous incorporation of fresh human feedback:
- Incremental Retraining: Regular updates to both reward and policy models based on new annotations, preference data, and observed model failures. Incremental retraining ensures that improvements accumulate over time without overwriting previously learned aligned behaviors.
- Dynamic Feedback Loops: Automatic selection of edge cases, low-confidence outputs, or problematic generations for re-annotation. This creates a targeted feedback cycle that prioritizes areas where the model is uncertain or prone to errors, improving sample efficiency and reinforcing safe, high-quality behaviors.
- Feedback Scheduling: Combining real-time user feedback with curated expert evaluations to refine model performance. Structured scheduling can include continuous logging of user interactions, periodic expert audits, and synthetic challenge sets to evaluate emerging capabilities or safety concerns.
- Evaluation Integration: Human-in-the-Loop systems are paired with monitoring dashboards that track alignment and safety metrics. For example:
- Reward model prediction accuracy on newly annotated data.
- Changes in safety benchmark scores after policy updates.
- Frequency of edge-case failures identified by human reviewers.
- Trends in hallucination, bias, or toxicity metrics.
- Operational Oversight: Annotator performance, guideline adherence, and quality metrics are continuously assessed to maintain the reliability of the human feedback pipeline.
This integration keeps the model aligned over time, prevents drift as human expectations or use cases evolve, and ensures that human insight continuously guides learning.
To summarize, without a tightly integrated infrastructure linking annotation, data management, reward modeling, reinforcement learning, and human oversight, RLHF cannot scale effectively. Successful systems rely on seamless orchestration between humans and machines, continuous monitoring for safety, and carefully engineered training loops that balance performance, alignment, and stability. By embedding metrics, dashboards, and iterative human feedback within the training cycle, organizations can maintain robust, adaptive RLHF pipelines that improve models reliably over time.
4.2.5 Key Takeaways
- RLHF aligns AI behavior with human values: By using human preference data to guide learning, RLHF bridges the gap between standard model objectives (like likelihood maximization) and what humans actually consider helpful, safe, and accurate.
- Human feedback drives reward modeling: High-quality preference data is essential for training reward models that reliably capture human judgments, forming the foundation for effective reinforcement learning.
- Iterative feedback loops improve alignment: Repeated cycles of policy generation, reward evaluation, and policy updates allow models to gradually refine their behavior, reducing undesirable outputs and reinforcing responses that meet human expectations.
- Infrastructure is key to scalability: Robust annotation platforms, secure and versioned data pipelines, distributed training systems, and comprehensive monitoring are necessary to maintain efficiency, reproducibility, and safety at scale.
When implemented thoughtfully, RLHF reduces unsafe or biased outputs, enhances usefulness across diverse tasks, and ensures AI systems behave in ways that more closely reflect human preferences and values. This combination of human oversight and technical infrastructure makes RLHF a practical approach for producing aligned, reliable, and trustworthy AI models.
4.2.6 Pseudocode RLHF Example
Objective
This section provides a high-level conceptual view of RLHF through pseudocode, emphasizing the iterative nature of generation \(\rightarrow\) evaluation \(\rightarrow\) policy update. The goal is to help readers understand the workflow, without diving into framework-specific implementation details.
By the end of this section, readers should be able to:
- Understand the staged process of RLHF: How a pretrained base model is first adapted through supervised fine-tuning (SFT) and then further optimized using human feedback to produce an aligned policy model.
- Grasp the role of human feedback: How human preferences can be integrated either indirectly via a reward model or directly using preference-based methods like DPO, IPO, or GPO.
- Recognize the iterative loop: RLHF is not a single-step fine-tuning; it involves repeated cycles of output generation, evaluation against human-aligned signals, and policy updates, which gradually improve alignment.
- Comprehend the balance between learning and stability: How techniques such as KL regularization against a frozen SFT reference ensure that the model improves alignment without losing language fluency, factual accuracy, or instruction-following capabilities.
- Visualize modularity for experimentation: How different components - SFT, preference collection, reward modeling, and policy optimization - can be swapped or combined depending on the research goals, computational resources, and type of feedback available.
This section does not provide production-ready code, but instead offers clear pseudocode examples and best practice notes to illustrate the key principles, decision points, and trade-offs involved in building an RLHF training loop.
High-Level RLHF Pipeline Pseudocode
# Step 0: Load pretrained base LLM
base_model = PretrainedLLM()
# Step 1: Supervised Fine-Tuning (SFT)
sft_model = fine_tune(base_model, instruction_dataset)
# Step 2: Create frozen reference and policy model
reference_model = freeze(sft_model) # Frozen for KL regularization
policy_model = copy(sft_model) # This is the model that will be updated
# Step 3: Collect human preference data
# Could be pairwise comparisons or multi-output rankings
# We need some interface for collecting human preference data
preferences_dataset = collect_human_preferences(policy_model, prompts)
# Step 4: Train reward model
# Only for classical RLHF (including the Reward Model)
reward_model = train_reward_model(preferences_dataset)RLHF/Policy Optimization Loop
Using a Reward Model (Classical RLHF with PPO/GRPO)
# RLHF/Policy Optimization Loop
# 1. Using a Reward Model (Classical RLHF with PPO/GRPO)
for iteration in range(num_iterations):
# Generate candidate outputs
outputs = policy_model.generate(prompts)
# Compute reward scores for the: <prompt, output> pair
rewards = reward_model.score(outputs)
# Compute PPO loss with KL regularization to reference model
# Compute log probabilities under the policy model
log_probs_policy = policy_model.log_probs(prompts, outputs)
# Compute log probabilities under the frozen reference model
log_probs_reference = reference_model.log_probs(prompts, outputs)
# Compute KL divergence penalty
kl_penalty = log_probs_policy - log_probs_reference
# Combine reward and KL penalty
adjusted_reward = rewards - beta * kl_penalty
# Compute PPO loss
policy_loss = compute_ppo_loss(log_probs_policy, adjusted_reward)
# Update policy model weights
policy_model = gradient_step(policy_model, policy_loss)
# Periodically collect new human preference data from current model outputs
# to improve the reward model or preference dataset
if iteration % refresh_interval == 0:
# Collect human comparisons
new_preferences = collect_human_preferences(policy_model, prompts)
# Add them to the existing dataset
preferences_dataset += new_preferences
# Retrain or fine-tune the reward model
reward_model = train_reward_model(preferences_dataset)Using Direct Preference Optimization (DPO/IPO/GPO)
This loop illustrates online preference optimization: the policy generates outputs, humans provide preferences, and the model is updated directly from those comparisons.
# Define function to calculate the Preference Loss
def convert_preference_to_loss(new_preferences):
# Element: List[tuple(string, string, string)]
# new_preferences = [(prompt, positive_output, negative_output), (prompt2, ..., ...)]
# Define preference_loss
preference_loss = 0
# Iterate through all new preferences
for prompt, y_plus, y_minus in new_preferences:
# Log-probabilities of preferred and rejected responses under the policy
log_prob_pos = policy_model.log_prob(prompt, y_plus)
log_prob_neg = policy_model.log_prob(prompt, y_minus)
# DPO-style loss: encourages preferred outputs
loss = -log(sigmoid(beta * (log_prob_pos - log_prob_neg)))
preference_loss += loss
# Average over all new comparisons.
preference_loss /= len(new_preferences)
return preference_loss
# Define function for calculating the KL penalty
def kl_penalty(policy_model, reference_model, prompts, outputs):
# Compute log probabilities under the policy model
log_probs_policy = policy_model.log_probs(prompts, outputs)
# Compute log probabilities under the frozen reference model
log_probs_reference = reference_model.log_probs(prompts, outputs)
# Compute KL divergence penalty
kl_penalty = log_probs_policy - log_probs_reference
return kl_penalty
# 2. Using Direct Preference Optimization (DPO/IPO/GPO) (without a Reward Model)
for iteration in range(num_iterations):
# Step 1: Generate candidate outputs for the current prompts
outputs = policy_model.generate(prompts)
# Step 2: Collect human preference comparisons
# Each element: (prompt, preferred_response, rejected_response)
new_preferences = collect_human_preferences(prompts, outputs)
# Step 3: Compute preference loss directly from the collected comparisons
preference_loss = convert_preference_to_loss(new_preferences)
# KL penalty keeps the updated policy close to the frozen SFT reference
kl = kl_penalty(policy_model, reference_model, prompts, outputs)
total_loss = preference_loss + kl
# Update policy model weights
policy_model = gradient_step(policy_model, total_loss)
# Optionally add new preferences to the dataset for future iterations
if iteration % refresh_interval == 0:
preference_dataset += new_preferencesNotes/Best Practices
- Frozen reference model: Always keep a frozen SFT copy as a KL regularization reference to preserve language quality and instruction-following behavior.
- Iterative updates: RLHF is inherently iterative. Repeat cycles of generation, evaluation, and policy optimization, refreshing preference data as needed.
- Choice of evaluation:
- Reward model-based RLHF: suitable when a large preference dataset exists and you want a continuous reward signal.
- Direct preference optimization (DPO/IPO/GPO): simpler, stable, bypasses reward modeling, works well with pairwise or ranked data.
- Policy update constraints: Always use KL or other regularization terms to prevent catastrophic drift from the SFT behavior.
- Monitor alignment metrics: Continuously evaluate outputs for helpfulness, factual correctness, and safety.
- Resource efficiency: Start with smaller batches and fewer prompts for prototyping. Scale up carefully when infrastructure allows.
- Modular design: Keep reward modeling, preference collection, and policy optimization modular, so that experiments with different algorithms (PPO, GRPO, DPO, IPO) are straightforward.
Further Reading
If you want to dive deeper into RLHF implementations, we recommend checking out the following tutorials:
- RLHF from Scratch Tutorial: Colab Notebook | GitHub (ashworks1706 2023)
- Beginner-Friendly RLHF Pipeline Guide (Medium) Building an RLHF Pipeline for LLMs (Ha 2025)
Note: You may also want to check some specific Reinforcement Learning datasets, like the following one: HF lmsys/chatbot_arena_conversations (LMSYS 2023)
These resources provide hands-on examples and step-by-step explanations to help you understand RLHF in practice.
4.3 Efficient Inference and Test-Time Compute
As Large Language Models (LLMs) grow in size and reasoning capability, their Inference Efficiency becomes a critical engineering and research challenge. Once a model has been trained, it enters the Inference Phase, where it is used to generate outputs for new inputs such as user queries or tasks. Unlike training, where the model updates its parameters through large-scale optimization, inference simply uses the learned parameters to predict the most likely next tokens and generate a response (see Figure 4.3 and Exxact Corporation (2017)).
Most modern language models generate text autoregressively, meaning that tokens are produced sequentially, one after another, each conditioned on the prompt and the tokens generated so far. As a result, the cost of producing an answer grows with the length of both the input and the generated output. For example, in response to a user prompt like:
User: What is the capital of France?
The model might generate the answer token by token:
Answer: The capital of France is Paris.
Because this generation process is sequential, the computational cost increases as responses become longer.
Recent models have also become capable of Chain-of-Thought (CoT) Reasoning, a technique where the model generates intermediate reasoning steps before arriving at a final answer. Instead of directly producing a short response, the model may articulate a sequence of logical steps, calculations, or intermediate conclusions that lead to the solution. This behavior is typically encouraged during later training stages such as supervised fine-tuning (SFT) or reinforcement learning (RL), where the model is exposed to examples that include reasoning traces. Generating these intermediate steps often improves performance on tasks that require structured reasoning such as mathematics, coding, or planning. However, this also means that the model must produce many more tokens before reaching the final answer. An example of CoT reasoning is shown in Figure 4.4.
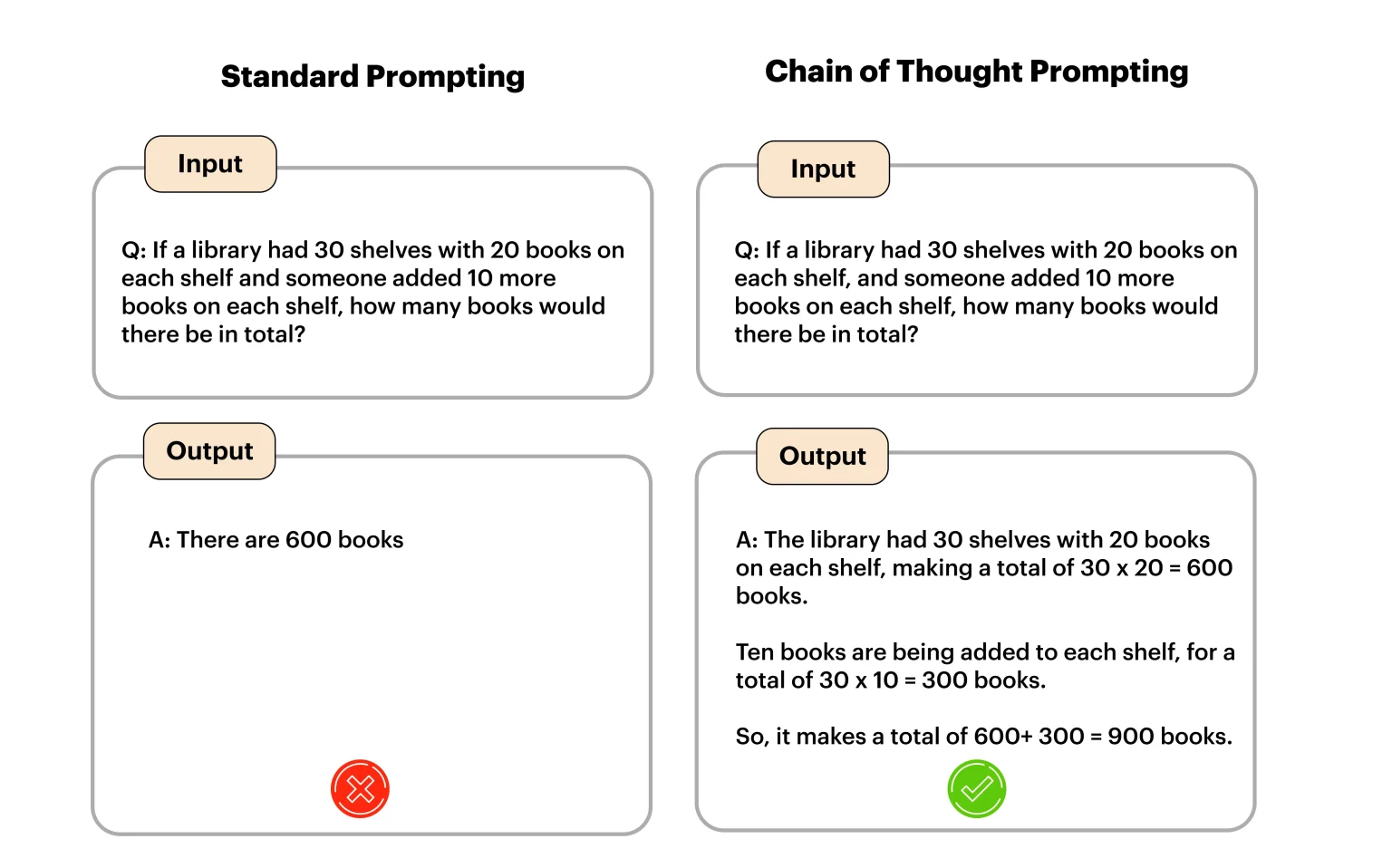
The computation required to process inputs and generate outputs during inference is often referred to as Test-Time Compute (TTC). TTC encompasses all computational resources used when the model is deployed, including processing the prompt, generating tokens step by step, and maintaining intermediate representations such as attention caches. Because techniques like Chain-of-Thought increase the number of generated tokens, they can significantly increase test-time compute and therefore latency, energy consumption, and infrastructure cost.
In addition to the model and its reasoning behavior, the prompt given to the model also plays an important role in determining inference cost. Because prompts are converted into tokens that the model must process before generating a response, their length and structure directly influence inference cost. Longer prompts require more computation and memory during inference, especially when working with large models or long context windows. For this reason, prompt design is not only important for model behavior but also for efficiency and system performance.
As reasoning-capable models become more widely deployed, optimizing the entire inference process becomes essential for achieving the right balance between accuracy, latency, and infrastructure cost. This chapter explores core strategies for improving inference efficiency in reasoning-oriented models, including system-level optimizations, memory management techniques, and prompt optimization techniques that reduce test-time compute while maintaining output quality.
4.3.1 Chain-of-Thought (CoT) Reasoning
Chain-of-Thought (CoT) reasoning is a process where a language model generates intermediate steps or reasoning traces before producing a final answer. Instead of giving a direct response immediately, the model “thinks step by step” breaking a complex problem into smaller parts and summarizing intermediate conclusions along the way.
Comparison between CoT and Standard Models:
- Standard Models generate outputs directly from the prompt to the answer, often without explicit intermediate reasoning.
- CoT-Enabled Models produce additional tokens that represent the reasoning process, which can help ensure logical consistency and accuracy, especially for multi-step problems, calculations, or planning tasks (see Figure 4.4).
Most reasoning models acquire the Chain-of-Thought skill typically during later training stages, where the focus shifts from general language modeling to structured reasoning and task-specific behavior:
- Supervised Fine-Tuning (SFT): The model is trained on curated datasets that include explicit reasoning steps or intermediate calculations. For example, instead of just seeing a question and its final answer, the model is shown the step-by-step reasoning leading to that answer. This teaches the model how to “think” in structured steps, making it more reliable for multi-step tasks.
- Reinforcement Learning (RL): After SFT, the model can be further refined with feedback-driven training, where outputs are evaluated based on correctness, coherence, and reasoning quality. The model is rewarded for producing logical, stepwise reasoning, which encourages it to follow structured thought patterns rather than jumping directly to answers. RL can also help the model prioritize useful intermediate steps that improve final output accuracy.
By combining SFT and RL, reasoning models internalize CoT behavior: they learn not only the language patterns of reasoning but also which reasoning steps are effective for solving complex tasks. This allows the model to generate multi-step solutions more reliably while still producing a concise final answer if needed.
Why CoT Models are useful?
CoT helps models by giving them more tokens to think with, which allows them to break complex problems into smaller, manageable steps. Each intermediate token represents a partial calculation, logical deduction, or summary of the reasoning so far. By explicitly generating these steps, the model can track its own thought process, avoid skipping critical steps, and catch potential errors before producing the final answer.
This stepwise process also enables the model to summarize intermediate results, remember previous conclusions, and combine them when forming the final response. For example, in a multi-step math problem, the model can compute sub-results sequentially, reducing the chance of arithmetic mistakes. Similarly, in code generation or planning tasks, CoT allows the model to consider dependencies and constraints across steps, which improves coherence and correctness.
Overall, CoT reasoning often boosts performance on tasks requiring multi-step logic, such as mathematics, coding, planning, or reasoning over text. Even if the intermediate steps are not shown to the user, they provide an internal scaffold that guides the model toward more accurate, structured, and reliable final answers.
Reasoning-Steps Visibility
In many applications, the intermediate reasoning produced by CoT is not directly shown to the end user. These reasoning steps function as an internal scaffold that guides the models decision-making process. Even though the user sees only the final answer, the model uses the chain of intermediate steps to verify calculations, track logical dependencies, and reduce errors.
In practice, CoT can therefore be seen as a means to an end: it allows the model to reason methodically behind the scenes, producing structured, high-quality results without necessarily exposing the intermediate reasoning to the user. In some systems, parts of the CoT may be selectively surfaced but most of the time it remains internal computation that enhances the final response.
4.3.2 Understanding Test-Time Compute (TTC) and Reasoning Models
Test-Time compute (TTC) refers to all the computational resources a model consumes when generating an output. This includes the time, energy, and hardware resources required to process the input, perform internal computations, and produce the final response. Optimizing TTC is especially important for reasoning-capable models because these models often generate longer outputs or intermediate reasoning steps, which directly increase computational cost.
Prefill vs Decode Stages
LLM inference typically consists of two computational stages:
Prefill Stage
- The model processes the entire input prompt in parallel.
- All tokens in the prompt are passed through the transformer to initialize internal states, most notably the KV-cache (see Section 4.3.3.4 for more details).
- This stage is compute-heavy but highly parallelizable.
Decode Stage
- The model generates new tokens autoregressively, one token at a time.
- Each new token attends to all previous tokens using the KV-cache, which is updated after every generation step.
- This stage is sequential and often dominates Latency.
For models using CoT reasoning, the decode phase can become significantly longer, as the model generates many intermediate reasoning steps before producing the final answer.
Reasoning models often hit computational bottlenecks due to:
- Longer Generation Sequences: Explicit reasoning traces or multi-step outputs increase the number of tokens generated.
- Higher Per-Token Computation: Larger context windows or attention mechanisms require more calculations for each token.
- Complex Decoding Behavior: Generating text is not always a simple “pick the most likely next word” process. Advanced decoding strategies, such as beam search, temperature sampling, or speculative decoding, modify the decoding process to balance quality, diversity and latency.
- Beam Search keeps track of multiple possible token sequences at each step to find the most likely overall output. This multiplies the number of predictions the model makes per token to improve final output quality.
- Temperature Sampling introduces randomness to make outputs more diverse, which can require additional sampling and probability calculations.
- Speculative Decoding generates multiple tokens ahead of time using a smaller draft model and verifies them with a larger model. While some draft computations may be discarded, the goal is to reduce wall-time latency by parallelizing token generation rather than strictly minimizing total compute or total floating-point operations. So, in reasoning models, where outputs are already longer due to Chain-of-Thought steps, these complex decoding strategies can further increase test-time compute because the model must repeat these computations for each intermediate reasoning token as well as the final answer.
- Context Growth: Extended prompts, background information, or previous reasoning steps increase the number of tokens processed for each query.
Because of these factors, reasoning models naturally require careful consideration of latency, memory usage, batching strategies and other system-level optimizations to manage test-time compute effectively. The following sections explore these considerations in detail, covering techniques that help balance performance, cost, and output quality.
4.3.3 Considerations around Latency, Batch Size, Memory Usage during Inference
When deploying reasoning-capable models, three factors dominate inference performance: latency, batch size, and memory efficiency.
These dimensions interact closely (improving one often impacts the others), so practical optimization requires balancing them together.
Figure 4.5 illustrates a simplified architecture of a typical LLM serving pipeline. Multiple client applications send requests to an inference server, which processes these queries through several components before returning a response (Dayan et al. 2024). At a high level, the flow works as follows:
- Client Requests: End-user applications send requests to the server using protocols such as HTTP or gRPC. These requests typically contain the prompt, configuration parameters (temperature, max tokens, etc.), and sometimes additional context.
- Query Queue and Scheduler: Incoming requests are placed into a query queue, where a scheduler determines how they should be processed. The scheduler decides when requests should be executed and how they should be grouped together for efficient GPU usage.
- Dynamic Batching: The engine often performs dynamic batching, where multiple requests arriving within a short time window are grouped together and processed simultaneously on the GPU. This improves throughput by maximizing hardware utilization. However, batching can introduce additional latency, since requests may briefly wait in the queue before execution.
- Inference Engine: The batched requests are passed to the model inference engine, which runs the neural network (e.g., Deep Learning runtimes such as PyTorch, TensorRT, etc). This stage performs the main computation, generating tokens sequentially using the models parameters. For reasoning models, this stage is particularly expensive because:
- Outputs are often longer.
- Attention mechanisms process longer contexts.
- Intermediate states such as KV-caches must be maintained in memory.
- Model Management: The serving system may manage multiple models simultaneously, loading them from a model registry and allocating them across GPUs. Efficient model management ensures that the correct model is loaded and that GPU memory is used effectively.
- Hardware Layer: At the bottom of the stack, the computations run on hardware accelerators such as GPUs, TPUs, or other AI accelerators. GPU memory capacity and bandwidth strongly influence how many requests can be processed concurrently and how large the model or context window can be.
- Metrics and Monitoring: Systems continuously track metrics such as troughput, latency, and GPU utilization. These metrics help operators tune batch sizes, scheduling policies, and memory allocation to improve performance.
This architecture highlights why Latency, Batch Size, and Memory Usage are tightly interconnected:
- Increasing Batch Size improves throughput but can increase latency.
- Larger Models or Longer Reasoning Traces increase memory consumption.
- Efficient Scheduling and Batching Strategies are required to keep GPUs fully utilized without delaying user responses.
The following sections explore these three dimensions Latency, Batching, and Memory Usage in more detail and describe practical techniques used in modern LLM serving systems.
Latency
Latency refers to the total time required for a system to process a request and return a response.
In the context of LLM inference, latency typically includes several stages:
- Request Processing Time: Receiving the request, parsing the prompt, and scheduling the query.
- Prefill Stage: Processing the input prompt through the model to initialize internal states (e.g., attention caches).
- Decoding Stage: Generating output tokens sequentially.
- Post-Processing and Response Delivery: Formatting and returning the generated response to the client.
In practice, latency is often measured using metrics such as:
- Time to First Token (TTFT): How long it takes before the model generates the first output token after the start of the prefill stage.
- Time per Output Token (TPOT): The average time required to generate each additional token. It does not include the prefill time and is often used to measure the efficiency of the decoding stage.
- End-to-End Latency: The total time from request submission to the final response.
Strategies to Reduce Latency
Reducing latency requires both Model and System Level Optimizations. Several techniques are commonly used in modern LLM serving systems to improve latency:
- Speculative Decoding: Speculative decoding accelerates generation by using a smaller or faster model to predict multiple tokens ahead of time. The larger model then verifies these predictions in parallel. If the predictions are correct, multiple tokens can be accepted at once, reducing the number of sequential decoding steps required via the larger model.
- Parallel or Asynchronous Decoding: Some parts of the inference pipeline can be parallelized or executed asynchronously. For example, input preprocessing, request scheduling, and GPU execution can be overlapped to reduce idle time and improve response speed.
- Pipeline Parallelism and Model Sharding: Large models can be split across multiple GPUs. With Pipeline Parallelism (see Figure 4.6), different layers of the model run on different devices, allowing computation to overlap. Tensor Parallelism (see Figure 4.7) can also distribute large matrix operations across multiple GPUs, reducing per-device load (Xu et al. 2021).
- Kernel Fusion and Graph Optimization: Modern deep learning runtimes optimize execution by combining multiple GPU operations into a single kernel. This reduces memory transfers and kernel launch overhead, which can significantly improve inference speed.
- Low-Overhead Serving Frameworks: Specialized inference frameworks are designed to minimize system overhead and maximize GPU utilization. Examples include:
- vLLM: Optimized for high-throughput LLM serving and efficient KV-cache management.
- TensorRT-LLM: NVIDIA’s optimized runtime for transformer inference on GPUs.
- Triton Inference Server: A production-grade inference server supporting dynamic batching, model management, and performance monitoring.
- SGLang: Framework designed for efficient LLM serving and complex reasoning workflows, providing optimized execution for structured prompts, tool use, and multi-step generation. These frameworks implement many low-level optimizations that reduce latency and improve scalability in production environments.
Batch Size
Batch size refers to the number of input requests that are processed simultaneously by the model during inference. Instead of running the model separately for each request, modern inference systems group multiple requests into a batch and execute them together on the GPU.
Batching is important because GPUs are highly parallel devices. When multiple inputs are processed at the same time, the system can amortize the Computational Overhead of large matrix operations and memory transfers across many requests. As a result, increasing batch size typically Improves Throughput, meaning the total number of requests the system can process per second.
However, batching also introduces trade-offs, particularly in interactive applications where users expect fast responses.
Throughput vs Latency Trade-off
Larger batch sizes improve throughput, but they can negatively affect latency.
- Higher Throughput: When many requests are processed together, GPU resources are utilized more efficiently, allowing the system to serve more queries per second.
- Higher Latency: Requests may need to wait in a queue until enough inputs accumulate to form a batch, delaying the response for individual users.
Because of this trade-off, production systems often balance Batch Size and Latency requirements depending on the use case. For example:
- Interactive Applications (Chatbots, Assistants): Prefer smaller batches and lower Latency.
- Offline Processing (Document Summarization, Dataset Inference): Prefer larger batches to maximize Throughput.
Challenges with Batching in LLM Inference
Batching becomes more complex for autoregressive language models due to several factors:
- Sequential Token Generation: During decoding, the model generates tokens one step at a time. Each step must wait for the previous token to be generated, which limits how efficiently requests with different output lengths can be batched together.
- Memory Constraints: Each request requires memory for:
- Model activations: Intermediate tensors produced at each transformer layer during the forward pass. These activations represent the internal representation of the input as it propagates through the network. Even though inference does not require storing gradients (as in training), activations must still be temporarily stored while computing the output of each layer.
- Attention computations: Attention mechanisms require computing large matrices representing interactions between tokens in the sequence. These attention score matrices and related intermediate tensors consume additional memory, particularly for long input contexts or large batch sizes.
- KV-cache Storage for previous tokens: During autoregressive decoding, the model stores Key (K) and Value (V) tensors for every previously generated token in each transformer layer. These cached tensors allow the model to avoid recomputing attention over earlier tokens, significantly speeding up generation. However, the KV-cache grows with the Sequence Length, Number of Layers, and Batch Size, making it one of the main memory bottlenecks in large-scale LLM inference. So, shortly, as batch size increases, the memory required for these components also grows, which may limit the maximum batch size that fits on a GPU.
- Padding Inefficiency: Requests within a batch often have different Sequence Lengths. Since GPUs operate on fixed tensor shapes, shorter sequences must be padded to match the longest sequence in the batch. The model still performs computations for these padded tokens even though they contain no useful information. Example of Padding Inefficiency:
| Input ID | Sequence | Token Length |
|---|---|---|
| 1 | “What is 2+2?” | 6 |
| 2 | “Explain how quantum computing works.” | 15 |
| 3 | “Summarize this paragraph…” | 22 |
If three inputs of 6, 15, and 22 tokens are batched together, the model computes 22 tokens for Every Sequence due to padding. This means a significant portion of the computation is wasted on dummy tokens. So, grouping inputs with similar lengths can reduce this inefficiency.
Best Practices for Efficient Batching
Several techniques are commonly used to balance Throughput, Latency, and Memory usage:
- Dynamic Batching: Dynamic batching groups requests that arrive within a small time window and processes them together automatically. This allows systems to increase GPU utilization without forcing requests to wait too long in a queue.
- Sequence Bucketing: Requests are grouped into batches based on Similar Sequence Lengths. By batching sequences of comparable size, the system reduces padding overhead and improves Computational Efficiency.
- Micro-Batching: Instead of forming large batches, some systems process many small asynchronous batches. This approach helps maintain low latency while still benefiting from some degree of parallel execution.
- Batch-Aware Scheduling: Advanced serving systems dynamically adjust batch sizes based on current GPU Load, Request queue size, and Latency targets. This allows the system to balance real-time responsiveness with efficient hardware utilization.
- Continuous Batching: also called In-Flight Batching, combines elements of dynamic and micro-batching by merging requests that are already being processed but have not started computation into a single batch. This reduces idle GPU time and maximizes Throughput without adding noticeable latency for individual requests.
Modern Inference frameworks such as vLLM, TensorRT-LLM, Triton Inference Server, and SGLang implement advanced batching strategies to maximize GPU efficiency while maintaining acceptable latency for users.
Memory Efficiency
Memory usage is often the largest bottleneck when deploying Large Language Models, particularly for reasoning-capable models that generate long outputs or process large prompts. Unlike traditional ML inference workloads, LLM inference must keep several large data structures in GPU memory simultaneously while generating tokens sequentially.
In practice, GPU memory during inference is primarily consumed by three components:
- Model Weights
- Intermediate Activations
- Attention Cache (KV-cache)
Understanding how each component contributes to memory usage is essential for designing efficient inference systems.
Model Weights
Model weights are the learned parameters of the neural network. During inference, these weights must be loaded into GPU memory so that each layer of the transformer can perform matrix multiplications and attention operations.
Large transformer models often contain billions of parameters, and each parameter requires a certain number of bytes depending on the numerical precision used:
| Precision | Bytes per Parameter |
|---|---|
| FP32 | 4 bytes |
| FP16/BF16 | 2 bytes |
| INT8 | 1 byte |
| FP8 | 1 byte |
Because of this, memory consumption scales linearly with model size. For example:
- A 7B parameter model (FP16) requires roughly 14 GB of GPU memory just for weights.
- A 70B parameter model can require 140 GB or more, which exceeds the memory of a single GPU.
This is why large models often require multi-GPU deployment or Weight Compression techniques such as quantization.
Activations
Activations are temporary tensors produced at each layer during the forward pass of the model. These tensors contain intermediate representations of the input and are passed from one transformer layer to the next.
During inference, activations are generally smaller than during training because gradients are not stored. However, they can still become large depending on several factors:
- Long Input Prompts
- Large Batch sizes
- Large Hidden Dimensions
For reasoning models, activations may grow significantly because prompts often include:
- Multiple instructions
- Contextual documents
- Reasoning traces
- Tool outputs or intermediate steps
In some cases, especially with long contexts, Activation Memory can approach or exceed the size of the Model Weights themselves.
Attention Cache (KV-Cache)
The Key-Value cache (KV-cache) is typically the largest and fastest-growing memory component during inference.
Transformers rely on a self-attention mechanism where each token attends to all previous tokens in the sequence. Recomputing attention for every previous token at every decoding step would be extremely expensive. To avoid this, models store the Key (K) and Value (V) tensors generated for each token in each layer.
These cached tensors allow the model to reuse previously computed attention information instead of recomputing it. However, the KV-cache grows linearly with both:
- Batch Size (number of sequences processed in parallel)
- Sequence Length (number of tokens processed so far)
- Number of Transformer Layers (each layer maintains its own KV-cache)
- Hidden Dimension (size of the vector representing each token)
- Attention Heads (multiple parallel “views” of attention)
This makes long prompts and reasoning traces particularly expensive. Efficient KV-cache management is therefore one of the most important challenges in LLM inference systems.
Optimization Techniques
Several techniques can reduce memory usage and enable more efficient deployment of Large Language Models.
- Quantization
- Reduces the number of bits used to store weights and activations (e.g., FP32 → FP16 → INT8 → FP8).
- Benefits: Cuts memory usage by 1-4×, reduces bandwidth, and often accelerates inference.
- Limitations: Lower precision can slightly reduce numerical stability or model accuracy, careful calibration or Quantization-Aware Training is required (Zmora et al. 2021).
- Reduces the number of bits used to store weights and activations (e.g., FP32 → FP16 → INT8 → FP8).
- Sharding and Offloading
- Sharding: Split the model across multiple GPUs, distributing layers or tensor slices to avoid a single device bottleneck.
- Offloading: Move less-frequently used tensors (weights, KV-cache, or intermediate activations) to CPU memory and fetch them on demand.
- Benefits: Allows deployment of models larger than a single GPU can hold.
- Limitations: May increase Latency and reduce Throughput due to device-to-device or CPU-GPU data transfers.
- Paged or Sliding Window Attention
- Paged Attention: Organizes the KV-cache into fixed-size memory blocks (“pages”) that can be dynamically allocated and reused, improving GPU memory utilization during long sequences. Those chunks (“pages”) can be swapped in and out of GPU memory dynamically (Kwon et al. 2023).
- Sliding Window Attention: Model only keeps the KV-cache for the most recent tokens inside a fixed window. Tokens outside this window are no longer part of the KV-cache and therefore are not contributing to attention.
- Benefits: Enables efficient Long-Context Inference and prevents KV-cache memory from growing uncontrollably.
- Limitations: Sliding windows may lose information from earlier tokens and therefore, reduce model accuracy slightly for tasks that require global context. And paged attention introduces additional implementation complexity.
- Mixed-Precision Inference
- Compute activations in FP16 or BF16 instead of FP32.
- Benefits: Reduces memory footprint of activations by ~2× with negligible impact on reasoning accuracy.
- Limitations: Some operations may suffer from numerical instability (small errors in calculations like rounding or approximation grow exponentially during computation and leads to inaccurate and incomplete results), especially for very deep or highly sensitive models. Requires hardware support (e.g., NVIDIA Tensor Cores).
- Prefix Caching
- Many production prompts share common prefixes, such as system instructions, task descriptions, or few-shot examples.
- Instead of recomputing the transformer states for these shared tokens, inference systems can Reuse Previously Computed KV-Cache Entries.
Combined Effect:
By applying these techniques, it is possible to reduce GPU Memory Usage drastically, allowing:
- Longer Reasoning Chains (extended CoT outputs)
- Larger Batch Sizes
- Deployment of bigger models on commodity hardware
4.3.4 Prompt Templating, Quantization, and Pruning
As Large Language Models (LLMs) grow in size and reasoning capability, efficiently managing Test-Time Compute becomes critical. Below we cover strategies that help optimize inference by reducing memory usage, lowering latency, and improving throughput without compromising output quality.
We start with Prompt Templating, a method for structuring inputs consistently to improve response quality and reduce unnecessary computation. Next, we explore Quantization and Pruning, techniques that compress model weights and activations to reduce memory footprint and accelerate inference.
Together, these approaches address both input design and system-level optimizations, providing practical tools for deploying reasoning-capable LLMs efficiently.
Prompt Templating
Prompt templating refers to the practice of structuring prompts using reusable templates rather than constructing prompts dynamically for every request. A template defines a consistent format for how instructions, context, and user queries are organized before being sent to the model.
Prompt engineering refers to the usage of such structured prompts to guide a model toward producing accurate, useful, and consistent outputs. Careful prompt design can improve response quality, reduce ambiguity, and avoid unnecessary computation during inference.
In production systems, prompts typically contain multiple components such as:
- System instructions describing the model’s role or behavior.
- Task descriptions explaining what the model should do.
- User input or query.
- Optional context documents or retrieved information: Additional background information, documents, or constraints relevant to the task.
- Optional examples (one/few-shot demonstrations): The prompt includes a small number of examples that illustrate the desired output format or reasoning pattern.
Instead of rebuilding this structure for every request, prompt templating allows systems to reuse a predefined prompt structure (see Figure 4.8), inserting only the variable parts (e.g., the user query or retrieved context). This improves both efficiency and consistency across requests.

Why Prompt Templating Improves Inference Efficiency
Prompt templating helps reduce Test-Time Compute in several ways:
Reduced tokenization overhead: Prompts must be converted into tokens before the model processes them. If large parts of a prompt remain constant across requests (e.g., instructions or formatting rules), templating allows these components to be pre-tokenized and reused, avoiding repeated tokenization work.
Smaller and Cleaner Prompts: Templates encourage developers to design minimal and structured prompts, avoiding unnecessary text. Since inference cost scales with the number of input tokens, shorter prompts reduce:
- Compute required during the prefill stage.
- Attention Computations over the prompt.
- Memory Usage for activations and KV-cache.
Improved Caching Opportunities: Consistent prompt formats enable prefix caching techniques used in modern inference frameworks. If multiple requests share the same prompt prefix (for example, identical instructions or system prompts), the model can reuse previously computed intermediate representations instead of recomputing them.
More Predictable Model Behavior: Using consistent prompt structures reduces variability in model responses. This improves reproducibility and simplifies evaluation, debugging, and system integration.
Controlling Output Length
Prompt templating can also help control Generation Length, which directly impacts Test-Time Compute. Developers often combine templates with mechanisms such as:
- Stop tokens: Predefined tokens that signal the model to stop generating text.
- Maximum Token Limits: Caps on output length.
- Length Penalties: Mechanisms that discourage excessively long outputs.
To wrap up, Prompt Templating is a simple but effective optimization technique that reduces tokenization overhead, prompt size, and redundant computation during inference. By standardizing prompt structure and reusing common components, production systems can lower test-time compute while maintaining consistent and reliable model behavior.
Quantization
Quantization is a technique used to improve Inference Efficiency by representing model parameters and intermediate values using lower numerical precision. Instead of storing values in high-precision formats such as FP32 (32-bit floating point), quantization converts them into smaller formats such as FP16, INT8, or FP8.
The main idea is that many neural network parameters do not require full 32-bit precision to produce accurate predictions. By reducing the number of bits used to represent each value, quantization Reduces Memory Consumption, Lowers Memory Bandwidth Requirements, and Accelerates Computation during inference.
This is particularly important for large language models, where billions of parameters must be loaded into GPU memory and used repeatedly during token generation.
Why Quantization Improves Inference Efficiency
Quantization improves performance primarily through three mechanisms:
Reduced Memory Footprint: Lower precision formats require fewer bits per parameter. For example:
Precision Bits Relative Memory FP32 32 1× FP16/BF16 16 ~2× smaller INT8 8 ~4× smaller FP8 8 ~4× smaller
Reducing the size of model weights allows larger models to fit on a single GPU or enables higher Batch Sizes and Longer Context Windows.
Lower Memory Bandwidth Usage: During inference, large matrices must be repeatedly loaded from GPU memory. Smaller representations reduce the amount of data transferred between memory and compute units, which can significantly improve performance.
Faster computation: Modern GPUs and specialized AI accelerators often include hardware units optimized for Low-Precision Arithmetic (e.g., NVIDIA Tensor Cores). These units can perform operations on FP16, INT8, or FP8 values more efficiently than FP32 operations.
Main Quantization Methods
Several quantization strategies are commonly used in LLM inference systems.
Post-Training Quantization (PTQ): Post-training quantization converts model weights to lower precision after the Model has been trained, without requiring additional training. Typically, weights trained in FP32 are converted to FP16 or INT8 (see Figure 4.9), sometimes using a small calibration dataset to adjust scaling factors and minimize accuracy loss. PTQ is widely used because it is fast to apply, compatible with many pretrained models, and supported by most inference frameworks (e.g., TensorRT, ONNX Runtime, vLLM).
KV-Cache Quantization: During autoregressive generation, the Key-Value (KV) Cache stores attention tensors for every previously generated token. This cache grows with both the sequence length and the number of transformer layers, making it one of the largest memory consumers during inference. KV-cache quantization compresses these tensors using lower precision formats such as INT8 or FP8, significantly reducing memory usage when generating long outputs or reasoning traces. This optimization is particularly valuable for Chain-of-Thought Reasoning, where models generate long intermediate reasoning sequences.
Activation Quantization: In addition to compressing model weights, some systems also apply quantization to Activations, the intermediate representations computed at each layer during the forward pass of the model. They store temporary results that are passed to the next layer. Although they are not permanent parameters like model weights, activations can consume significant memory when processing long sequences, large batches, or deep transformer networks. Activation quantization reduces memory usage and can improve throughput when supported by hardware. However, activations can be sensitive to precision loss, so careful calibration or mixed-precision strategies are often used.
Benefits
Quantization can significantly improve inference efficiency:
- Up to 4× lower memory footprint, allowing larger models to run on limited hardware.
- Faster Inference Throughput due to reduced memory bandwidth and optimized hardware execution.
- Enables Larger Batch Sizes and Longer Context Windows.
- Reduces infrastructure cost for large-scale deployment.
Limitations
Despite its benefits, quantization introduces some trade-offs:
- Accuracy Degradation: Extremely low precision formats may slightly reduce model performance, especially for sensitive tasks such as reasoning or code generation.
- Calibration Requirements: Proper scaling and calibration are often required to maintain model quality.
- Hardware Dependence: Performance gains depend on whether the underlying hardware supports efficient low-precision operations.
For these reasons, many production systems use Mixed-Precision Approaches, where some parts of the model remain in higher precision while others are quantized to achieve the best balance between efficiency and accuracy.
Pruning
Pruning is a model compression technique that improves Inference Efficiency by removing parameters or structural components of a neural network that contribute little to the model predictions. The underlying intuition is that large neural networks are often Over-parameterized, meaning that many weights have minimal impact on the final output.
By removing these less important parameters, pruning reduces the number of computations required during inference, leading to lower latency, reduced memory usage, and improved hardware efficiency.
In transformer-based LLMs, pruning can target several parts of the architecture, including:
- Individual weights inside linear layers.
- Attention heads in the multi-head attention mechanism.
- Hidden channels in feed-forward networks.
- Entire transformer layers or blocks.
The goal is to remove redundant components while preserving the model’s ability to generate accurate outputs.
Pruning Techniques
Two main categories of pruning are commonly used in deep learning systems.
Unstructured Pruning: Unstructured pruning removes individual weights within layers based on some importance criterion (for example weights with small magnitudes). This approach creates sparse weight matrices where many elements are zero.
While this method allows for very fine-grained compression, it often provides limited speed improvements on standard GPU hardware. This is because dense matrix multiplication kernels still process zero values unless specialized sparse computation kernels are used.
As a result, unstructured pruning is more commonly used for model compression or storage reduction rather than direct inference acceleration.
Structured Pruning: Structured pruning removes entire components of the network, such as:
- Attention heads
- Neurons or channels
- Feed-forward network dimensions
- Full transformer layers
Because these components are removed completely, the resulting model has smaller dense matrices, which directly reduces the number of floating-point operations (FLOPs) required during inference.
Structured pruning is therefore much more compatible with modern GPU and accelerator hardware, making it the preferred approach for improving inference latency.
Reasoning-Aware Pruning
Recent research suggests that different parts of transformer models contribute differently to reasoning capabilities. Studies such as (Song et al. 2025) show that mid-to-late transformer layers tend to play a larger role in complex reasoning tasks, including multi-step problem solving and logical inference.
Early layers are often responsible for basic linguistic processing and token representation, while deeper layers perform more complex transformations that support reasoning and structured generation.
Because of this, Selective Pruning of Early Layers or Less Critical Components can reduce model size and computation without significantly degrading reasoning performance.
Empirical studies show that this type of pruning can achieve:
- 20-30% Faster Inference
- Minimal Loss in Reasoning Accuracy
This approach is often referred to as Reasoning-Aware Pruning, as it considers the functional role of different layers when deciding which components to remove (Lucas et al. 2025).
Benefits
Pruning can significantly improve the efficiency of large language models:
- Reduced Latency: Fewer parameters and operations lead to faster token generation.
- Lower Compute Cost: Smaller models require fewer floating-point operations per token.
- Smaller Memory Footprint: Fewer parameters and intermediate computations reduce memory usage.
- Improved Deployment Flexibility: Pruned models are easier to run on smaller GPUs.
Limitations
Despite its advantages, pruning also introduces several challenges:
- Accuracy Trade-Offs: Aggressive pruning may degrade model performance, particularly for complex reasoning tasks.
- Loss of Reasoning Depth: Removing too many layers or attention heads can reduce the model’s ability to perform multi-step reasoning.
- Hardware Limitations: Unstructured sparsity often provides limited speedups unless the hardware and inference runtime support sparse operations.
For these reasons, pruning is often combined with other techniques such as Quantization, Distillation, and Mixed-Precision Inference to achieve the best balance between model efficiency and output quality.
4.3.5 Summary of Key Takeaways
| Optimization Area | Techniques | Efficiency Impact |
|---|---|---|
| Latency | Speculative decoding, key/value caching, model sharding | Lower response time and faster token generation |
| Batching | Dynamic batching, continuous (in-flight) batching, sequence bucketing, micro-batching | High GPU Utilization and improved Throughput |
| Memory Efficiency | Quantization, CPU/GPU Offloading, Mixed-Precision Inference | Run larger models and longer contexts on limited GPU Memory |
| Attention Optimization | Paged attention, Sliding window attention, KV-cache quantization | Efficient handling of long contexts and reasoning traces |
| Prompt Optimization | Prompt templating, structured prompts, prompt caching | Fewer input tokens and reduced Test-Time Compute |
| Model Pruning | Structured pruning, reasoning-aware pruning | Reduced FLOPs, faster inference with minimal accuracy loss |
| Generation Control | Stop tokens, Max Token Limits, Decoding Strategies | Prevent excessively long outputs and control inference cost |
| System-Level Optimization | Efficient runtimes, Scheduling, Distributed Inference | Scalable deployment of Reasoning Models |
Notes/Best Practices
The following best practices summarize the most important guidelines for deploying Reasoning-capable Language Models efficiently:
Control Output Length When Using Chain-of-Thought: Reasoning models often generate long intermediate reasoning traces. While this can improve accuracy, it also increases inference latency and computational cost. Whenever possible:
- Limit generation length using Max Token Limits or Stop Tokens.
- Use reasoning traces only when the task truly requires multi-step reasoning.
- Consider hiding intermediate reasoning from the user while still allowing the model to reason internally. This does not reduce the computational cost, but it can improve user experience by removing unnecessary detail.
Optimize Prompt Design: Prompts directly influence the number of tokens processed during inference. Good prompt engineering practices include:
- Be Clear and Specific about the task.
- Provide Relevant Context when needed.
- Define the Output Format or Style explicitly.
- Show Examples using few-shot prompts when appropriate.
Shorter and more structured prompts reduce unnecessary token processing and improve consistency.
Reuse Prompt Templates and Shared Prefixes: Production systems often reuse the same instructions or system prompts across many requests. To reduce redundant computation:
- Use Prompt Templates for consistent formatting.
- Enable Prefix Caching when the same prompt prefix appears frequently.
- Avoid repeatedly sending large context blocks when not required.
This can significantly reduce the Prefill Cost during inference.
Efficient serving systems rely on batching to maximize GPU utilization: Best practices include:
- Use Dynamic Batching to group requests arriving close in time.
- Use Continuous (in-flight) Batching to avoid GPU idle time.
- Apply Sequence Bucketing to reduce padding inefficiency.
However, for interactive applications, avoid overly large batches that increase response latency.
Monitor and Optimize Memory Usage: Memory is often the main constraint when deploying large models. Key strategies include:
- Use Mixed Precision (FP16/BF16) inference.
- Distribute Large Models across GPUs.
- Apply Quantization when supported by the hardware.
- Optimize KV-Cache Storage for long generation sequences.
- Use Paged Attention or Sliding-Window Attention for long contexts.
Efficient memory management allows Larger Models and Longer Contexts to run on limited hardware.
Choose the Right Inference Framework: Modern inference engines provide optimized kernels and scheduling mechanisms. Examples include:
- vLLM
- TensorRT-LLM
- Triton Inference Server
- SGLang
See examples of how to run Inference Frameworks in our MINERVA-benchmarks GitHub repository or our Website.
These frameworks provide features such as Continuous Batching, Optimized Attention Kernels, and Efficient KV-Cache Management.
Apply Model Compression When Necessary: If deployment constraints are strict, Model compression techniques can reduce inference cost. Common approaches include:
- Quantization
- Structured Pruning
- Knowledge Distillation
These techniques can reduce memory footprint and computational cost while maintaining acceptable accuracy.
Continuously Measure Inference Performance: Efficient inference requires monitoring key metrics such as:
- Latency per Request
- Throughput (Tokens/Requests per second)
- GPU Utilization
- Memory Consumption
Profiling these metrics helps identify bottlenecks and guide optimization efforts.
Overall Best Practice:
Efficient inference requires balancing Model Accuracy, Latency, Memory Usage, and Infrastructure Cost. Optimizing only one dimension may negatively impact the others, so practical systems must consider the full inference pipeline, from prompt design to model execution and serving infrastructure.
Practical Insight:
In many real-world deployments, the largest improvements in inference efficiency come not from changing the model itself, but from optimizing the Serving System, Batching Strategy, and Prompt Structure.